To keep resources secure in the Azure cloud environment, there are usually multiple levels of security that must be cleared for someone to be able to access a resource. For Azure SQL Databases, for example, the user who is trying to access the database must have access granted for their user account on the database but they also need to be given access for their IP address through the network firewall rules for the server or database resource.
I usually only need to add or update a single user’s firewall rule at a time when our business users get their IP addressed updated sporadically, but I had a situation last week where I needed to add over 40 firewall rules to an Azure SQL Server resource for a new database I imported on the server. I did not want to manually add that many firewall rules one at a time through the Azure Portal because that sounded tedious, boring, and like too many mouse clicks, so I instead figured out how to do it the fastest way possible–running a T-SQL script directly on the server or database through SQL Server Management Studio (SSMS).
Note: This would also work through Azure Data Studio or your chosen SQL Server IDE, I simply prefer to use SSMS so use that as a reference in comparison to completing the same actions directly through the Azure
What’s in this post
- Server vs. Database Firewall Rules
- T-SQL for Creating Firewall Rules
- How to Delete Firewall Rules Through SSMS
- Summary
Server vs. Database Firewall Rules
According to this Microsoft document, it should be possible to grant firewall rule access for a user to a single database on a logical Azure SQL Server resource. In my experience in Azure so far, we’ve only ever granted firewall access at the server level instead, since that is acceptable for our business use-cases. But since it’s possible to set the same firewall rules at the database level according to Microsoft, I added how to do that to this post, as well as the server-level rules which I will be creating for my use case.
T-SQL for Creating Firewall Rules
Did you know it was possible to create both database-level and server-level firewall rules for an Azure SQL Database through SSMS using T-SQL commands? I didn’t before I started this project request last week. Going forward, I will likely use the T-SQL route through SSMS when needing to make multiple firewall rules instead of using the Azure portal, to save myself time, effort, and mouse clicks.
Create a Server-Level Firewall Rule
To create new firewall rules at the server level, you can connect to your Azure SQL Server through SSMS and run the following command on the master database.
/* EXECUTE sp_set_firewall_rule N'<Rule Name>','<Start IP Address>','<End IP address>'; */
EXECUTE sp_set_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4';When you run that command, you are executing a built-in stored procedure that exists on the master database that will insert a new record for a server-level firewall rule into the table sys.firewall_rules, creating the server level firewall rule that will allow access through the specific IP address or IP address range. In the example above, I have the same value for both the Start IP Address and End IP Address parameters, but you can just as easily set that to a range of addresses, like 10.0.5.0 for the start and 10.0.5.255 as the end. I usually prefer to do that for a user’s IP address since our systems can change the last value fairly regularly, but since my current task was to grant access for servers, I set the start and end values to the same single IP address since I’m not expecting them to change frequently.
Create a Database-Level Firewall Rule
If instead of granting access to all databases on the server through a server-level firewall rule you would prefer to grant access to only a single database on your Azure SQL Server instance, you can do that as well. The T-SQL command to create a database-level firewall rule is the following. Notice how it’s very similar to the server-level command above, but with “database” specified in the stored procedure name.
/* EXECUTE sp_set_database_firewall_rule N'<Rule Name>','<Start IP Address>','<End IP address>'; */
EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4';The parameters that are required to run this database stored procedure are the same as what’s required for the server-level procedure, so you can either specify the same Start and End IP address values to allow access through a single address, or you can specify different values for the two to give access to a range of addresses. This procedure inserts records into the system table sys.database_firewall_rules on the database you ran the command on.
Speeding up the Creation of Execution Scripts
Knowing the above commands is helpful, and even works if you only have one or two firewall rules to add, but I promised I would tell you the fastest way possible to add 40+ firewall rules to a server, so how do I do that? How do I save myself the trouble of writing the above procedure execution commands 40+ times or copy/pasting/updating the line over and over again?
The trick I use is to generate my SQL queries in Excel, since Excel has the ability to concatenate strings and then to use the same formula across however many rows you have to generate the same concatenated string using multiple distinct values. I use this Excel trick quite frequently, whenever I need to generate the same type of SQL query/command multiple times based on specific values.
In this use case, I was provided a list of the names of the servers that needed inbound firewall access to my Azure SQL Database along with the IP addresses they would be using. I copied that information into two columns in Excel then wrote a formula in a third column to generate the SQL command that I needed to run to make a firewall rule for that particular server and IP address.
Here is an example of how I accomplish this type of task in Excel:
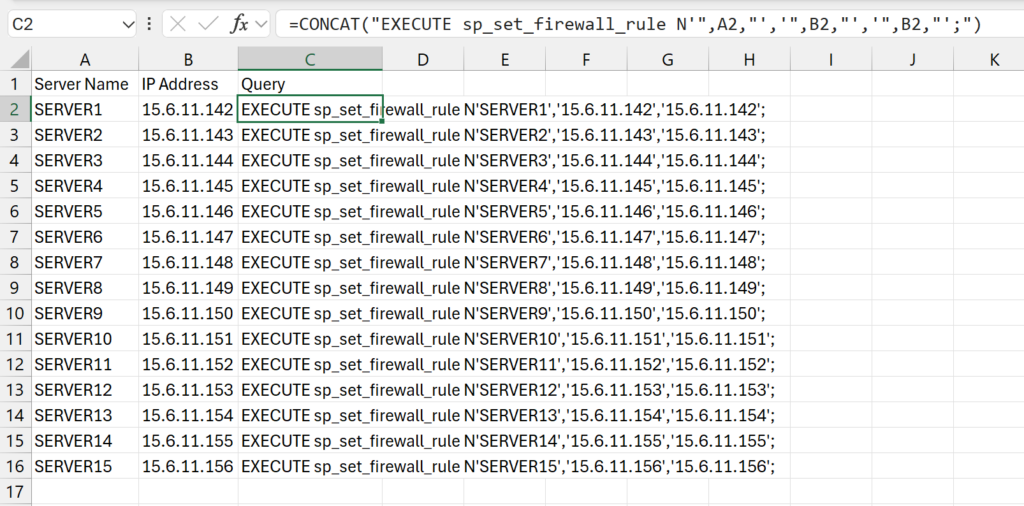
In Column A of the spreadsheet, I copied in the list of the server names I was provided. I am going to set the name of the firewall rule for each to the name of the server that is being given access. Column B then has the IP address that the server will be connecting through.
Note: all server names and IP addresses were made up for this example.
Then in Column C, I use the CONCAT function of Excel to generate the SQL query that I want, which I will then be able to copy to the database and execute to generate the firewall rule. The following is the full formula I used to generate the SQL command:
=CONCAT("EXECUTE sp_set_firewall_rule N'",A2,"','",B2,"','",B2,"';")After I’ve successfully made the command as I want it for the first server in the list, I then copy that same formula down the column for every row to generate the same command for each server and IP address combination. Once all the queries have been created, I copy the entire Column C into an SSMS query window:
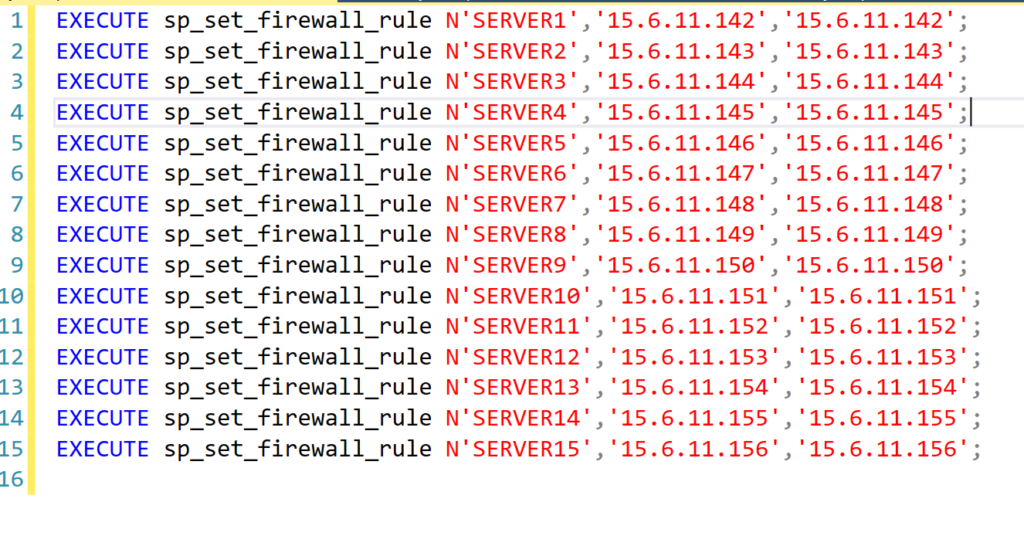
I then just have to click Execute and all the commands run, creating all the new firewall rules I needed in just a couple seconds. Believe me, this method of using Excel will save you a lot of time copying and pasting and updating IP addresses in the queries.
View existing Server-Level Firewall Rules Through SSMS
If you would like to review the list of server-level firewall rules that currently exist on your server, you can do so by running the following query on the master database of your Azure SQL Server instance.
select id, [name], start_ip_address, end_ip_address, create_date, modify_date
from sys.firewall_rules
order by idThis list will directly correspond to the list of values that you would see under “Networking” for your Azure SQL Server instance in the Azure portal.
View existing Database-Level Firewall Rules Through SSMS
If you would like to review the list of database-level firewall rules that currently exist on your database, you can do so by running the following query on the database you would like to see the firewall rules for.
select id, [name], start_ip_address, end_ip_address, create_date, modify_date
from sys.database_firewall_rulesAs far as I am aware, there is no way to view this same list of details from the Azure portal, so this should be the source of truth for database-level firewall rules for an Azure SQL Database.
How to Delete Firewall Rules Through SSMS
Similarly to how there is a more efficient way to create multiple firewall rules through T-SQL queries in SSMS, you can also quickly delete a lot of firewall rules at once through SSMS using a delete procedure. I haven’t yet had to delete a large number of firewall rules at once, but you can follow the same process I outlined above for adding them, but use the deletion procedure instead.
Delete Server-Level Firewall Rules
The T-SQL command you can use to delete a specified server-level firewall rule through SSMS is:
EXEC sp_delete_firewall_rule N'SERVER1';When deleting a rule, you only need to provide the name of the firewall rule you would like to delete.
Delete Database-Level Firewall Rules
The T-SQL command you can use to delete a specified database-level firewall rule through SSMS is:
EXEC sp_delete_database_firewall_rule N'SERVER1';When deleting a rule, you only need to provide the name of the firewall rule you would like to delete.
Summary
In this post, I outlined the full process I used to generate 40+ server-level firewall rules on my Azure SQL Server instance as requested. Before starting on this task I had no idea that it was possible to generate these firewall rules through a T-SQL command in SSMS, I only knew about adding them through the Azure portal manually. But like every good programmer, I knew there had to be a better and faster way and I was correct. I hope this post helps save you a little time as well the next time you need to add more than a couple firewall rules to your server.