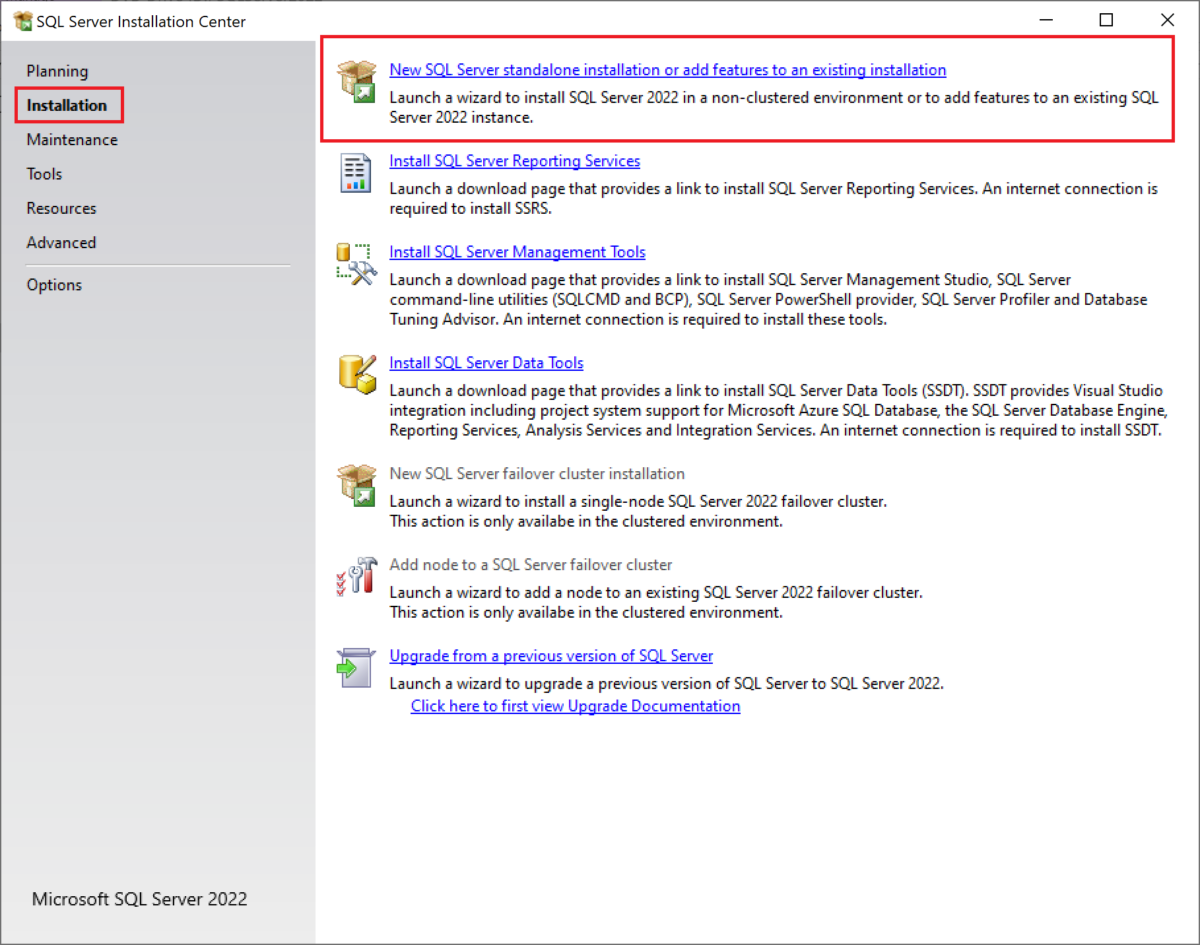
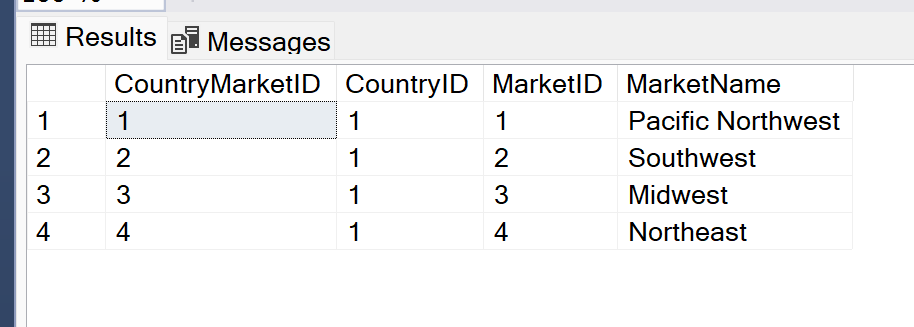
Today was my first day at Oracle Cloud World in Las Vegas, and also my first time ever at an Oracle conference, since I only recently started doing database administration with this RDBMS. As with any technology conference, the day was jam-packed with many different sessions. Although I obviously cannot convey all the information I learned at my sessions throughout the day, I will try to summarize the interesting and key points I took away from each.
What’s in this post
Keynote Session 1: “Customers Winning with the Cloud and AI”
I’m not going to lie, I went into this conference and this sessions not having a great opinion of Oracle, due to the multiple negative experiences I had with their database platform in the past few months. However, this keynote was not a useless session, because I did learn that MGM Resorts owns a huge number of properties and hotels in Las Vegas, which is interesting from a big data perspective, and that the CIA is the first customer of Oracle. There are a lot of rumors online about how Oracle came to be and how it may or may not relate to a CIA project codename, but I couldn’t find any reputable sources, so we’ll just leave it at the CIA being the first and one of the largest customers of Oracle.
Besides those interesting tidbits, this keynote mainly contained somewhat dry interviews with different large customers of Oracle talking about how they’ve utilized Oracle products to revolutionize their businesses and how they’ve started to use AI in their technology journeys. This was the beginning of discussions surrounding “AI” that continued throughout most of the sessions today. (On that topic, I’m starting to feel like the term “AI” is being watered down or misused at this conference to represent things that really shouldn’t fall under that term…)
“Accelerate Your IAM Modernization to Multi-cloud Deployments”
This session was not what I expected it was going to be, and it wasn’t the only one where that happened today. However, even though the content of this session wasn’t what I thought it was going to be, I did learn a few interesting things. The presenters gave many startling facts about the costs associated with data breaches as well as the causes of those breaches. The statistic that I found most interesting is their claim that 60% of breaches resulted from poor patch management.
I was hoping that this presentation was going to cover more of the technical details of implementing and modernizing IAM within the Oracle ecosystem, but it proved to be a general overview of what everyone should be doing instead, which was what disappointed me about it. However, it at least gave me some topics that I can do further research on by myself to learn more about IAM in Oracle, such as the Oracle Access Manager. At least if I couldn’t get the technical details I wanted, I still got some direction about what to research next.
“Create a Data Pipeline with Data Transforms in Autonomous Database Data Studio”
This presentation was more the style of what I was expecting of most of the sessions I chose today, but it once again covered completely different information than what I thought it would. This session was different than what I expected because I was not aware that “Data Transforms” is an Oracle product; I thought that it was being used as a general term in the title. If I had known that the presentation would be covering a specific service, I would have had a better understanding of what I was about to learn. My confusion of expectations did not make the presentation unenjoyable or uninformative, though.
What I learned from this session is that Oracle has two different ETL platforms available to move data around, similar to how Microsoft has SSIS for SQL Server (and other databases). Data Transforms was the service covered by this session, but they did mention Oracle Data Integrator (ODI) which is another, older ETL service. Data Transforms can move data between tons of different types of databases, not just Oracle, and it seemed to have a lot of interesting and easy to use ETL capabilities. It seems like they are trying to make this tool be the data flow tool of the future, especially since they covered 3 different features that are about to be added, like vector search/query capabilities. Although I haven’t had the chance to use this tool myself, I want to temper the expectations for what it can accomplish due to my own personal experiences with other Oracle services. Maybe it’s as fantastic and as useful as they say it is, or maybe it’s just another sales pitch that is better than the real user experience. If you have personal experience, good or bad, with Data Transforms I would love to hear about it in the comments below.
Keynote Session 2: “Oracle Vision and Strategy”
Of all the sessions today, I think this one had the most interesting pieces of information, although none of it was directly applicable to me or my company. The biggest downside of this keynote was that it went way over time, so I had to head out before the end of it. The two major topics of the keynote, presented by Larry Ellison, the founder and CTO of Oracle, were the joining of Oracle Cloud with the other major cloud providers and then covering various different topics surrounding artificial intelligence and how they want to use it to fix all the problems of the application and database development world.
While I like the idea of them putting Oracle databases into the other cloud platforms–Google Cloud Platform, AWS, and Azure–because it gives me hope that maybe one day we could migrate our Oracle databases to a less fragile ecosystem, it did leave me wondering if one day in the future there will just be one single mega-cloud system and monopoly originating from the combination of the current big four (but maybe I’ve just been reading too many dystopian novels lately).
I thought the second part of the keynote, surrounding current and potential uses of AI integration with other software systems, was more interesting and also a bit scary. Interesting in that automating mundane and error-prone processes makes our lives as database developers and administrators easier. There are so many things Mr. Ellison mentioned automating with AI that sounded great and useful to me. But it also scared me a bit, as it felt like there was an undertone of invasiveness being discussed under the guise of security. Security, on the technological and physical level, is important for individuals, groups, and even our whole country, but I personally believe security should not come at the cost of personal freedom and privacy. Some of the proposed and planned uses of AI, specifically how it relates to biometric authentication for every aspect of our lives, left me feeling a little uneasy (but once again, maybe it’s due to the large number of dystopian books I’ve read lately).
“Access Governance: The Key to Ensuring the Survival of Our Digital Lives”
I think this session was the best presentation of the day, as far as straight communication abilities go. The team of presenters was very well put together and knew their topics well without having to read off their slides at all, and I really appreciated that.
The topic of this session was once again about managing who can access what, including the use of Identity and Access Management (IAM) as one of the core topics. The presentation was lead by a member of the Oracle leadership team, who was accompanied by three Oracle customers, including a senior security engineer from Uber. Hearing from the different customers about their experience using IAM in general, not just the Oracle services, offered a great perspective on managing access to applications and databases, and gave me some ideas to take back to my own work. The main Oracle services covered were Oracle Access Governance and the Intelligent Access Dashboard, which I’ll need to do further research on myself now.
“AI-Based Autoscaling with Avesha for Simplified OKE Management on OCI”
This was my last session of the day, and although I was tired and dreaming of my hotel room, I did find it to be another interesting presentation, although not super applicable to my work life. The title is quite a mouthful, but what it covered was how a small company called Avesha has created 4 different tools to help you autoscale and manage Kubernetes clusters in Oracle Cloud Infrastructure (OCI). Their 4 tools all seemed like they would be very useful for people who are working with Kubernetes in Oracle, since apparently the autoscaling in OCI doesn’t always work as well as people want it to (coming from comments from the audience during the Q&A at the end of the presentation).
While I don’t think my company will be using any of Avesha’s tools anytime soon, they did seem like they could be extremely useful to other organizations. And the presenters definitely understood their own products, down to the fine details of how they work, which is always a green flag I appreciate with software vendors.
Summary
Wooh, that was a lot of information to recap and cover for a blog post! After attending these six sessions on this first day of Oracle Cloud World, I’m a little bit overwhelmed an exhausted, and not quite ready for another day and a half of more info dumps. But that’s okay because it’s what’s to be expected from conferences like this. I am hoping that the sessions I picked for tomorrow are more applicable to my current role, but even if they aren’t, I’m sure I’ll learn more interesting things throughout the day.