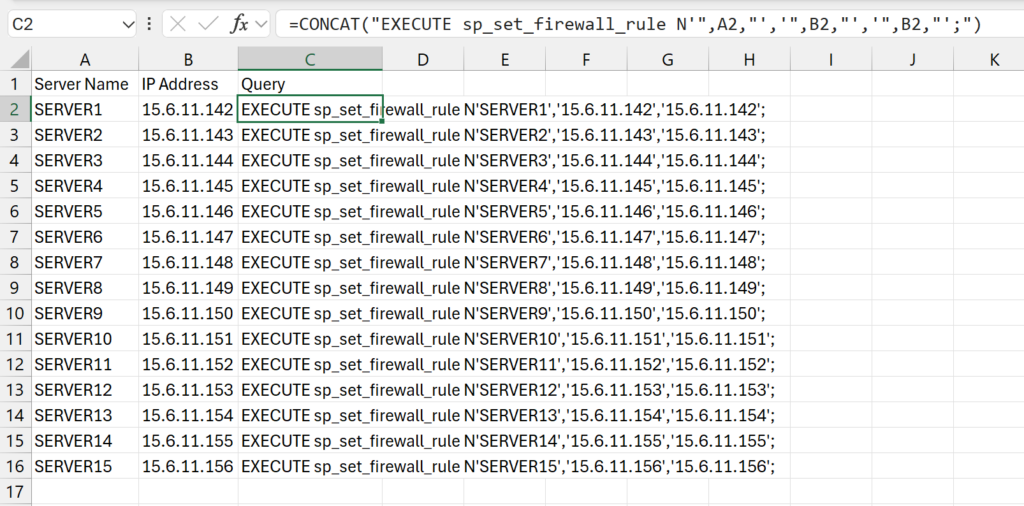
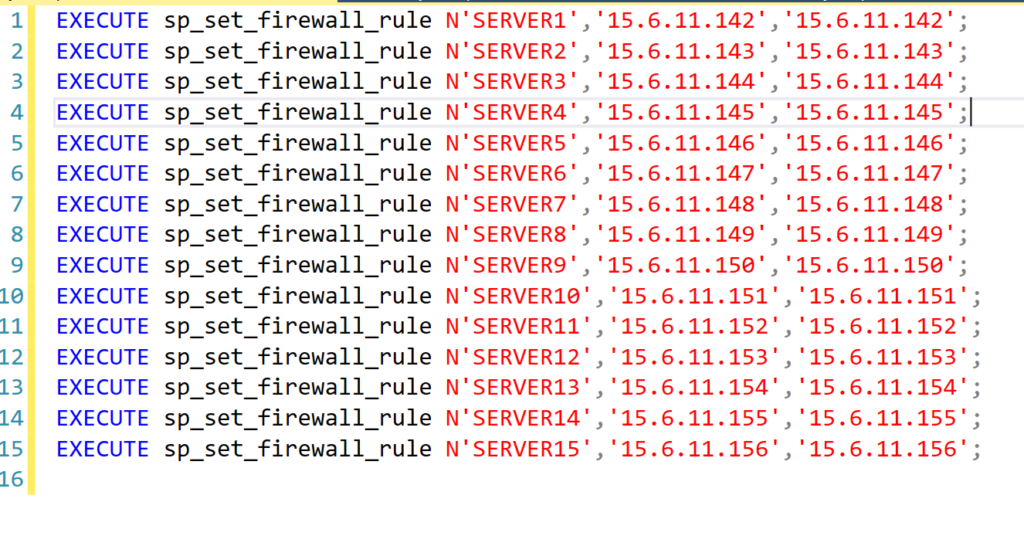
A task I was requested to implement a while ago in an Azure Synapse pipeline was to have the pipeline reseed a table identity column to prepare it for new data that will be calculated and inserted into the table as part of an optimizer solution someone is writing. This request challenged me to learn about identity reseeding since I had never even considered that would be something I would ever need to do, and it also challenged me to make that reseeding query work in a Synapse pipeline.
The process isn’t difficult, but it was a little finicky since a higher level of permissions is needed to run the reseeding command, and some people, like me, might not want to give their Synapse pipeline sysadmin permissions. This post will cover general information about what it means to reseed an identity column and then how you can do that reseeding from a pipeline.
What’s in this post
- Background
- So what does that have to do with identity columns?
- What is an identity column?
- How do I know if a column is an Identity?
- What is reseeding?
- How to manually reseed a column
- Permissions Needed to Run Reseed Query
- How to reseed an identity column from an Azure Synapse pipeline
- Summary
- Resources
Background
I completed a project where we upgraded the database servers for a business group, putting their main database onto an Azure Platform as a Service (PaaS) database instead of an old Azure virtual machine. Part of the project was to see if we could rewrite their optimizer into a new Python script instead of their current, very dated, C-based program that requires a VM to run on. Unfortunately, the business group decided to not go with my new script (as I mentioned in a previous post), so we had to come up with a way for them to continue running their current DLL program in the updated environment. For those who don’t know, the PaaS Azure databases no longer have the ability to run DLLs natively like on-prem or Infrastructure as a Service (IaaS) instances do, which meant that we had to find a way to continue running their program without the ability to run it natively on their upgraded database server.
The solution we came up with is to create a new and updated Azure IaaS VM that can run SQL Server and the DLL optimizer program. To get that to work and be cost-effective, when the time comes each month for their program to run, we are going to copy the relevant data for the optimizer from the main PaaS database into this VM’s database, the DLL will be executed which will calculate and load data into a couple of tables, then we will copy that calculated data back to the main server and power down the VM for the rest of the month.
So what does that have to do with identity columns?
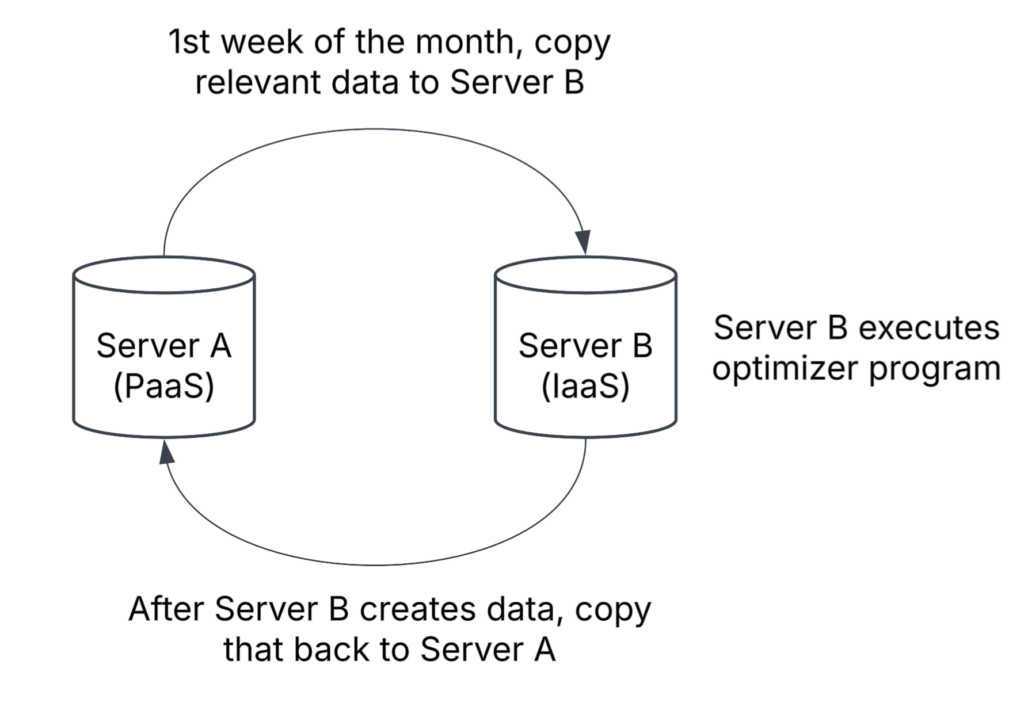
One of the tables that will have its data generated by the DLL, which will then be copied back to the main table on the main server, has an identity column. On Server A, the table contains customer data up to the beginning of the current month and the maximum identity column value is something like 165487998. On Server B, where the new data for this month will be calculated and prepared to be loaded back to Server A, the table also has that same identity column but the table is truncated each month before calculating the new data. That means that if we did nothing about the seed value for the table on Server B, the identity column value would restart at 1 and work its way up as new data was loaded, which would cause primary key conflicts when the data is loaded back to Server A. We need to prevent that issue and start the current month’s records at the identity value where we left off on Server A, so I needed to find a way to update the identity seed value for Server B’s table when the pipeline runs each month.
What is an identity column?
An Identity Column is a column in a SQL Server database table that has its value automatically generated when a new record is inserted into the table. These columns are frequently used for primary keys (PKs) because an Identity Column must be unique, which is perfect for PKs. When you create an identity column on a table, the default is to have the value of that column start at 1 and increment by 1 every time a new record is inserted. Those default values can be changed to fit your needs. The value that you want the column to start at is called the “seed”; the value you want to increment the column by is called the “Increment”.
For example, if I want to have a column that is automatically generated for me but I only want to have those values be even numbers, you can set the Seed for the column to be 2 and the Increment for the column to be 2, so the first value will be 2, the second will be 4, the third will be 6, and so on. But traditionally, I’ve only ever seen an Increment of 1 used, and I’ve never needed to set a different Seed value before this project.
How do I know if a column is an Identity?
Viewing the Column Properties
There are several ways to find out if a column is an Identity, but the method I use is to look at the properties of the column using the Object Explorer, whenever possible. In the Object Explorer for your server connection, navigate to the table you want to check for an Identity, expand the table, then expand “Columns”. Once you have the list of columns opened, you can right-click on any column and select “Properties” which is where you’ll find if it’s an identity or not.
Note: This method will not work with Azure PaaS servers, which severely limit the the information you can see from context menus and dialog windows.
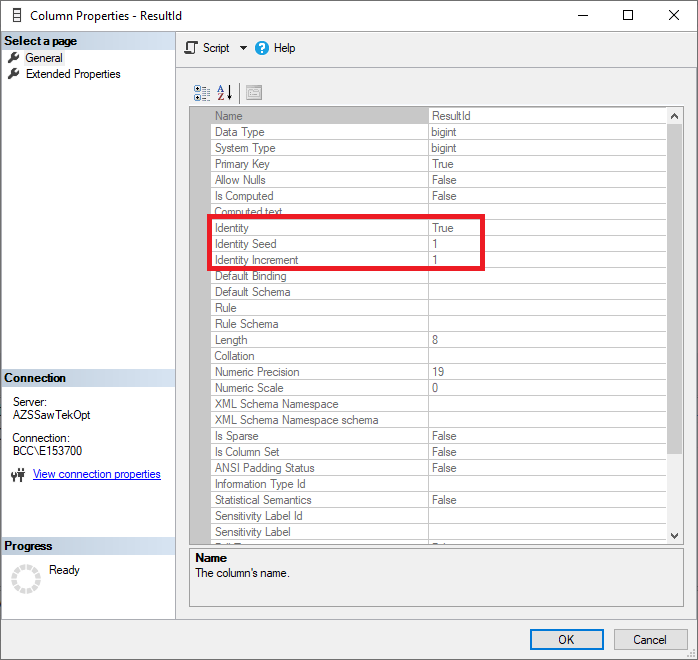
In the above screenshot showing the properties for my selected column, you can see that the value for the property “Identity” is set to “True” indicating that the column is an identity column. Then below that, you can see that the “Identity Seed” is set to 1 and the “Identity Increment” is also set to 1. Those two values mean that the first value that will be assigned to a row inserted into the table will be 1, then the value will go up by 1 for every new record inserted.
Scripting the Table
Another way you could quickly learn if a table has an Identity column and what the settings for that column is would be to right-click on the table in the Object Explorer and script the table to a new query window.
Once the script has been generated, you will easily be able to tell if a column is an identity because it will be included in the SQL query to generate the table.

Note: The values for Identity Seed and Identity Increment may not be accurate! In the screenshots above where I show how to find out if a column is an identity or not, both the Seed and Increment values show as being set to 1, but I know for sure that the Seed has been changed to a much larger value. The properties of the column may not reflect the actual values.
Finding identity columns on Azure SQL Databases
As I said in a note above, you cannot simply right-click on a column in the Object Explorer for an Azure SQL Database (PaaS database) and view the properties for the column like you can with IaaS or on-prem versions of SQL Server. To see whether a table has an identity column on Azure SQL Databases, you will either need to script out the table like the previous section said or you can use the following T-SQL query.
SELECT [object_id],
[name],
column_id,
system_type_id,
max_length,
[precision],
scale,
is_identity,
seed_value,
increment_value,
last_value
FROM sys.identity_columns
WHERE OBJECT_NAME(object_id) = 'TableName';
identity_columns viewWhen you run that query, you will see results like the following, which show the column that is an identity for the table. If the table doesn’t have an identity column, no results will be returned by the query.
Checking Identity Properties with DBCC CHECKIDENT
As I mentioned in a Note above, you can’t always trust that the values for Identity Seed and Identity Increment are correct in the Properties dialog or how they’re scripted out when you script out a table. So how do you know what the true values are? You can use the query on sys.identity_columns above or you can use the DBCC CHECKIDENT command.
DBCC CHECKIDENT ('dbo.TableName', NORESEED)Note: Be very careful with the formatting of that `DBCC CHECKIDENT` command, because changing the `NORESEED` value to anything else and running it could reset or change the seed value inadvertently. Use caution when using this command and make sure you have it set exactly as you want. See the resources section at the end of this post for more documentation about this command to familiarize yourself with it.
When you run that above command, it will output a message that tells you what the Identity Seed value is currently set to and what the highest value of the column is as well (for when the Identity value has been incremented above the Seed value). In my example, I have only added a single record to my table so that one record has the outputted identity value, and the current column value is the same as the seed since there’s only one record in the table.

CHECKIDENT function when you specify the NORESEED optionWhat is reseeding?
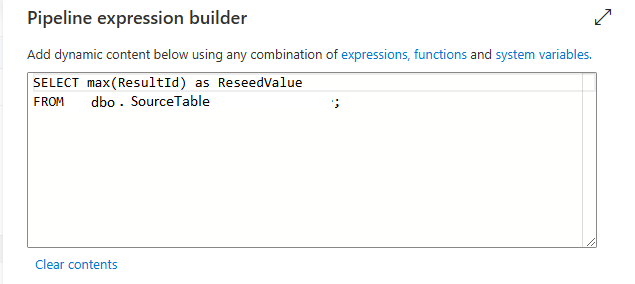
Reseeding is changing the value of the Identity Seed value for the Identity column so that it starts the value of the column at a number other than 1 or whatever it was originally set to. For my case, I need to retrieve the maximum value of the Identity column from Server A’s copy of the table, then set the Seed for Server B’s table to that value + 1 (so it starts at the next value above the current identity value in the source table). That means that I need to change the Seed value for my table on Server B to 128166810 instead of 1.
How to manually reseed a column
If you want to manually reseed an Identity column using a SQL command directly on the database, you can do so by using the following command:
DBCC CHECKIDENT ('dbo.TableName', RESEED, <NewSeedValue>);You can use variables with this command as well:
DECLARE @MaxIdentity int = 128166809;
DECLARE @ReseedValue int = @maxIdentity + 1
DBCC CHECKIDENT ('dbo.LengthAnalysisResultsHeader', RESEED, @ReseedValue);Permissions Needed to Run Reseed Query
According to the Microsoft documentation (linked in the Resources section at the bottom of this post), one of the following permissions needs to be assigned to the entity that is running the DBCC CHECKIDENT command:
- sysadmin server role
- db_owner database role
- db_ddladmin database role
But that document also specifically mentions that Azure Synapse requires db_owner.
How to reseed an identity column from an Azure Synapse pipeline
For my scenario, I don’t want to run the reseed command manually because the Seed value will be changing every month when our processing runs and generates new data. I have added the DBCC CHECKIDENT command to my Synapse pipeline that’s already loading the data between my two servers so that it’s reseeded automatically right when it needs to be.
In a Synapse pipeline, the reseeding based on a value from another server can be completed with two Lookup activities:
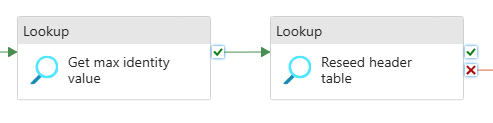
First Lookup Activity – Get the Identity value
The first Lookup will query the source database, in my scenario Server A, to get the maximum value for the column that is the Identity.
Second Lookup Activity – Set the Identity value
The second Lookup will run the DBCC CHECKIDENT command, which doesn’t return any results, and will then run a SELECT 1; to satisfy the requirements of the Lookup activity that something should be returned:
DECLARE @MaxIdentity int = @{activity('Get max identity value').output.firstRow.ReseedValue};
DECLARE @ReseedValue int = @maxIdentity + 1
DBCC CHECKIDENT ('dbo.TableName',RESEED,@ReseedValue);
select 1;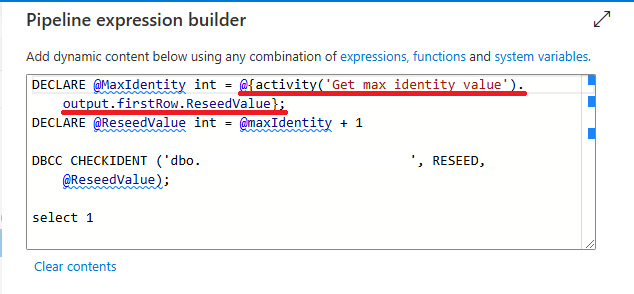
Let’s break that reseed query down a little more. The first line is creating a SQL variable called “MaxIdentity” which is an integer, and then setting the value of that variable to the output from the previous Lookup activity, which was called “Get max identity value”. To get the specific value from that preceding activity, we need to add .output after the activity call, then .firstRow to specify we want to get the value from the first row of the output of that activity, then finally add .ReseedValue which is the column name returned from the previous lookup activity.
DECLARE @MaxIdentity int = @{activity('Get max identity value').output.firstRow.ReseedValue};Summary
Reseeding the Identity column of a SQL Server table manually is a piece of cake because it only requires one small SQL statement. But to do the same process in an automated and repeatable manner is a different story. It’s not overly complicated to create a Synapse pipeline that reseeds a table’s Identity column on demand, but there are some quirks to getting the expressions to do so correctly which involved a lot of guessing and checking for me. I am still new to working with Synapse pipelines in-depth though, so perhaps this wouldn’t be such a difficult task for you more experienced Synapse developers. 🙂
If you run into any issues while setting up the above process yourself, I would love to help as much as I can, so please leave a comment below!
Resources
- How do I check the current identity column seed value of a table and set it to a specific value
- https://stackoverflow.com/a/44527414/17060311
- https://learn.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-checkident-transact-sql?view=sql-server-ver16