After a previous in-depth post about creating a Bicep template to deploy an Azure Infrastructure as a Service (IaaS) virtual machine, which included the use of a Custom Script Extension (CSE), I want to go more into depth about some of the trials I went through while trying to get the Custom Script Extension to work. Troubleshooting it wasn’t the easiest thing in the world, since Azure doesn’t give much feedback at all from the failure to deploy that resource from a Bicep template, so I am hoping I can give anyone else struggling to implement the Custom Script Extension resource to run a PowerShell script after deploying an Azure resource some assistance with their process.
This post only has the code for CSE itself, and not the rest of the template I use it in. If you would like to see the full template, please view it on my GitHub.
What’s in this post
- What is a Custom Script Extension resource?
- My use case for a Custom Script Extension
- My setup for a Custom Script Extension
- How the Custom Script Extension Works
- Issues with the Custom Script Extension
- Troubleshooting help
- Alternatives to this resource type
- Summary
What is a Custom Script Extension resource?
In the Bicep world of infrastructure as code templates in Azure, there is a resource type that is called a “Custom Script Extension” which isn’t so much a “resource” as you would normally expect in a Bicep template. Normally, a “resource” is what it sounds like: an Azure resource you want to create, like a server, network security group, database, and even things like role assignments. But for the Custom Script Extension, it’s a method of running a PowerShell script on a Virtual Machine (VM) resource after it has been deployed, to install software or do other necessary setup on the machine.
My use case for a Custom Script Extension
The reason why I use a Custom Script Extension in my Bicep template when I create an Azure IaaS VM is so that I can initialize the disks related to the VM so they can actually be seen and used like you would expect. For some reason, when you create an Azure VM with a Bicep template, it does not automatically join the created disks to the machine. Due to this, when you first log in to the machine after it has been created, you won’t see the disks in the File Explorer like you would expect. Thankfully, PowerShell and the Custom Script Extension allow me to initialize those disks and name them what we normally want them to be named without having to login to the server and do it manually myself.
I originally had my PowerShell (PS) script set to also join the machine to our corporate domain after it was created, but I recently removed that part because it would not work with the protectedSettings section of the extension description, which you’ll see below. If you want more details about why I couldn’t get this to work and thus had to remove the most problematic sections from my PS script, keep reading.
My setup for a Custom Script Extension
The following is the Bicep resource script I used as part of my wider IaaS VM creation script to setup the VM after it is deployed.
var initializeDisksScript = 'https://stgAcct.blob.core.windows.net/myContainer/SetUpWindowsVM.ps1'
var sqlExtensionName = 'SqlIaasExtension'
resource customScriptExtension 'Microsoft.Compute/virtualMachines/extensions@2024-07-01' = {
name: customScriptExtName
location:'westus2'
dependsOn:[sqlVM]
properties:{
publisher:'Microsoft.Compute'
type:'CustomScriptExtension'
typeHandlerVersion:'1.2'
settings:{
fileUris:[
initializeDisksScript
]
commandToExecute:'powershell -File SetUpWindowsVM.ps1'
}
protectedSettings:{
storageAccountName:storageAccountName
storageAccountKey:storageAcctKey
}
}
}A quick explanation of that definition is that it’s creating a resource of an extension type for VMs, and it’s dependent upon the VM which I specify further up in the full Bicep template. The script extension is set to execute a PowerShell command so that I can run a file called SetUpWindowsVM.ps1, which is downloaded by the script runner from the storage account location specified in a variable called initializeDiskScript. There are two different sections of “settings that you can specify: a normal settings section whose values will be output to the log after deployment, and then a section of “protected settings”, whose values do not get output to the log after deployment.
How the Custom Script Extension Works
After the Bicep template has created the VM, it will then set about running the specified script file I designated in my CSE resource definition. The first step to do that is to download the file from the specified fileUris location, which for me is an Azure Storage Account. The extension is able to connect to that Storage Account, since I provided the name and access key in the protectedSettings, and then download the file from there onto the local machine. The general location it’s downloaded to is: “C:\Packages\Plugins\Microsoft.Compute.CustomScriptExtension\1.*\Downloads\<n>”, where “1.*” is the version of Bicep you’re using and the “<n>” is a seemingly random integer value that the extension picks. For me, that was always “0”. After the file is downloaded, the CSE handler tries to execute the commandToExecute that you specified in your Bicep template. Since the PowerShell file will be downloaded locally to the area that CSE expects to use it from, you do not need to specify the full path to the file location, you can use the relative path formatting.
If you’re having issues with the CSE, like I was, you can get insight into what happened when the CSE ran by viewing the logs in this location: “C:\WindowsAzure\Logs\Plugins\Microsoft.Compute.CustomScriptExtension”. For more on that, see section below.
Issues with the Custom Script Extension
As of the time this was posted, I’ve been going back and forth with Microsoft support for several weeks to figure out how I could possibly use the commandToExecute specification in the protectedSettings object of the resource definition, and I have not yet resolved the error while working with them. The issue I am having is that the PowerShell script that I actually want to run includes the usage of a parameter containing a password, so I should use the protectedSettings to pass in the command with the password parameter so that the password is not output to the deployment log in plain text after the template is deployed. However, if I put the commandToExecute into the protected settings, nothing seems to happen and the script is not executed. If I put the same exact command into the normal settings, the script completes successfully yet my password it unsecurely output to the log, which I do not want.
Since I haven’t been able to resolve this problem, even with the help of Microsoft support, I have updated my PowerShell script to remove the section that joins the machine to the domain, which removes the need for me to pass through a password, so I can use the normal settings section to successfully call the commandToExecute. I am going to continue working with Microsoft support to see if we can finally come to a resolution, but I didn’t want to keep waiting on this post. If I ever fix the problem, I will update here.
Troubleshooting help
As I mentioned in the section above, you may run into random issues with the Custom Script Extension of Bicep (CSE) if you include it in your templates. Overall, I think it is still worth using this resource type, but you do need to be armed with some knowledge to help yourself as much as possible. These are the things I found useful when troubleshooting different issues with the CSE.
- You will need to delete your VM and redeploy it so many times while troubleshooting issues, so be ready for that. Thankfully, deleting a VM and all its associated resources through the Azure Portal has gotten a little easier recently, so that will save you a little time.
- If you are unsure whether the problem is with your PowerShell script or your Bicep template, create a test version of your VM as it would be created by your template (or run the template to create the VM then log on to that) and manually run the same PowerShell script on the machine. If it runs when you execute it manually, then the issue is not the PowerShell script but with the CSE.
- Do not create the CSE nested under the resource creation specification for the VM, list it as its own separate resource definition, like I have in my template. It’s much harder to understand what’s happening if you put it as a nested resource, and then you can’t troubleshoot it on its own because the entire VM creation will fail if the CSE fails.
- Make sure you specify the
dependsOnproperty in the CSE resource definition, or else it will likely get deployed out of order. Bicep is supposed to be smart enough to know that some things should be deployed before others, but it doesn’t seem to understand order of operations for the CSE. - To view the logs of the CSE after it’s been deployed to get a sense of what was happening, you can see that by going to the Deployments section of the resource group you deployed the template into. Open the specific deployment you created for your template, then click on the link for the CSE resource deployment.
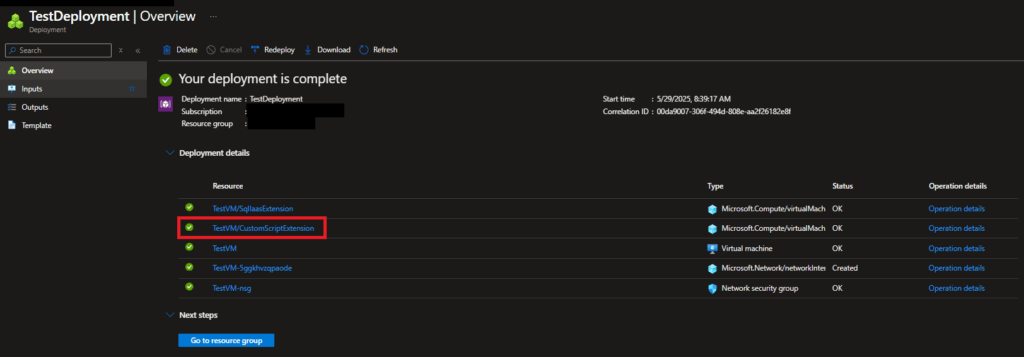
- Check to make sure the file downloaded onto the local machine by the CSE handler is the correct file. It would be in this general location on the machine: “C:\Packages\Plugins\Microsoft.Compute.CustomScriptExtension\1.*\Downloads\”. I never saw it be wrong, but it doesn’t hurt to double-check.
- Check the execution logs of the CSE after it runs on the machine. You can find all logs in this location on the machine after it’s been created and the CSE executed: “C:\WindowsAzure\Logs\Plugins\Microsoft.Compute.CustomScriptExtension”. The most useful log to me was the one called “CustomScriptHandler”, since that shows the exact steps the CSE handler ran when it executed your script (or tried to execute it).
- Set your PowerShell script to generate a log when it runs, because that will either tell you what happened and went wrong in PowerShell, or it will not be created at all like in my situation, showing that the CSE is the problem.
$scriptName = 'customScriptExtensionLog'
$scriptName = $scriptName.Split('.')[0]
$runtime = (get-date -Format 'hh-mm-dd-MM-yyyy')
$logfile = "D:\" + "$scriptName" + "-" + "$runtime" + '.txt'
Start-Transcript -Path $logfile- Review this Microsoft document for other troubleshooting information about the CSE.
Mostly, you will need a lot of time and patience to properly troubleshoot issues when the Custom Script Extension goes wrong.
Alternatives to this resource type
While I haven’t used this yet, there is an alternative resource type availabe to use instead of the Custom Script Extension (CSE), and it’s called RunCommand. If you would like to read more about this resource type to see if it would be a better fit for you, there is a great Microsoft blog about it.
Summary
While I may have gotten very frustrated using the Custom Script Extension resource type in Bicep recently, I still think it’s a very useful feature that could save you a lot of manual work in setting up a virtual machine, if you can get it to run the way you need. If you’ve also run into issues with this resource type, I would love to hear about them in the comments below! Otherwise, I will keep you all updated if I find a resolution to my specific issue after posting this.