
Welcome to another coffee break post where I quickly write up something on my mind that can be written and read in less time than a coffee break takes.
Several months ago I ran into a situation where I needed to update the records in one table based on values in a related reference table. To do this update, I was going to need to run an existing stored procedure once for every record in the reference table, which I believe contained information about countries and markets within those countries. The reference table looked something like this:
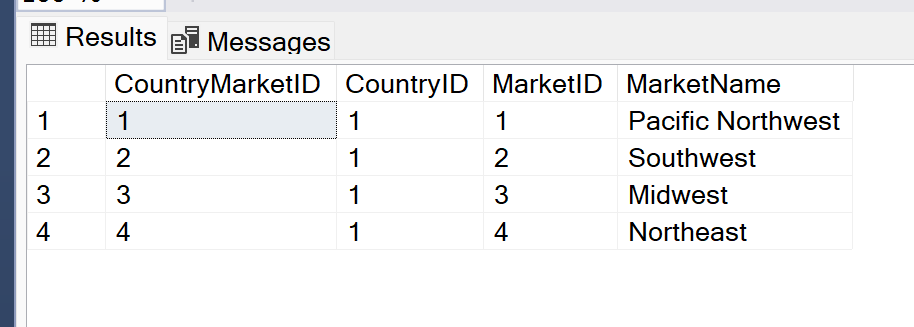
The stored procedure I needed to run had input parameters for CountryID and MarketID as well as several other things that aren’t important for this post. When I was originally looking at this task I needed to complete, I was not looking forward to running the stored procedure manually dozens of times, one for each combination of Country and Market. But I knew there must be a better way. I’m a programmer, I can find a way to automate this tediousness.
A practical use for a cursor
If you’ve developed SQL code for any length of time, you’ve probably heard an older DBA or database developer tell you to never use cursors! I know that I personally have been reminded of that many times, so I had never even considered using one or tried to use one. But when I was staring down the barrel of updating two values in a procedure execution call, running it, waiting for several minutes for the procedure to complete, then doing it all over again, for dozens of times, I knew I had to give a cursor a try.
I of course had to Google how to write a cursor, since I had never done that before, but was quickly able to write a script I would need. The cursor was created to loop over every record retrieved from the reference table using a query I wrote, and injected each of the CountryID and MarketID values into the input parameters of the stored procedure. This easily automated the tedious manual work that I would have needed to do myself, and it did it in a lot less time since it wasn’t a user having to slowly update each relevant value each time they needed to change.
Summary
Maybe cursors aren’t quite the devil I always believed them to be. I know they can certainly cause performance issues on databases when they’re written into stored procedures and ran regularly, turning what should be set-based work into row-based work, but I have learned that there is at least one fantastic use. And this use will make my life easier going forward any time I need to run one stored procedure a lot of times with different input values.
Sources
Here is the main StackOverflow answer I used to help me write my own query: https://stackoverflow.com/a/2077967. And you can see, the first comment of this answer is literally calling cursors evil, which I find amusing.
