
Before the holidays, I had the pleasure of doing the most recent round of patching for our production Oracle databases, to apply the patches that were released in late November. Similarly to how a lot of things behave unexpectedly in the IT world, I had different results of the patching in production compared to what happened in our test environments when I applied the same patches there first a few weeks before production. During the application of the patches in test, we had absolutely no issues, the patches applied seamlessly and it was super easy, although time consuming. Then in production, late at night on a Thursday evening when I should have been in bed already, the patches seemed to have been applied without issue again, except this time, my application developer teammates could not get their apps to connect to the database again once it came up.
What’s in this post
- The Error
- Helpful Commands
- How We Fixed the Problem
- Step by Step Solution to Update TNSNames.ora
- Summary
The Error
When my app dev teammate tried to reconnect his app to the newly patched server, he received an error similar to the following:
ORA-12514: TNS:listener does not currently know of service requested in connect descriptorThankfully my teammate used to deal with Oracle databases directly himself so he could help me run commands to troubleshoot what the app was encountering. We were quickly able to see that things weren’t right, but also we weren’t quite sure how to fix them.
Helpful Commands
The following commands were ones that helped us figure out what was wrong with the database after it had been patched. I ran these through a terminal connection to the node using PowerShell.
lsnrctl status
This command checks the current status of the listeners available on the system. When we ran the command, we got an output that looked like this, with status for a listener related to ASM but none of our container databases or pluggable databases:
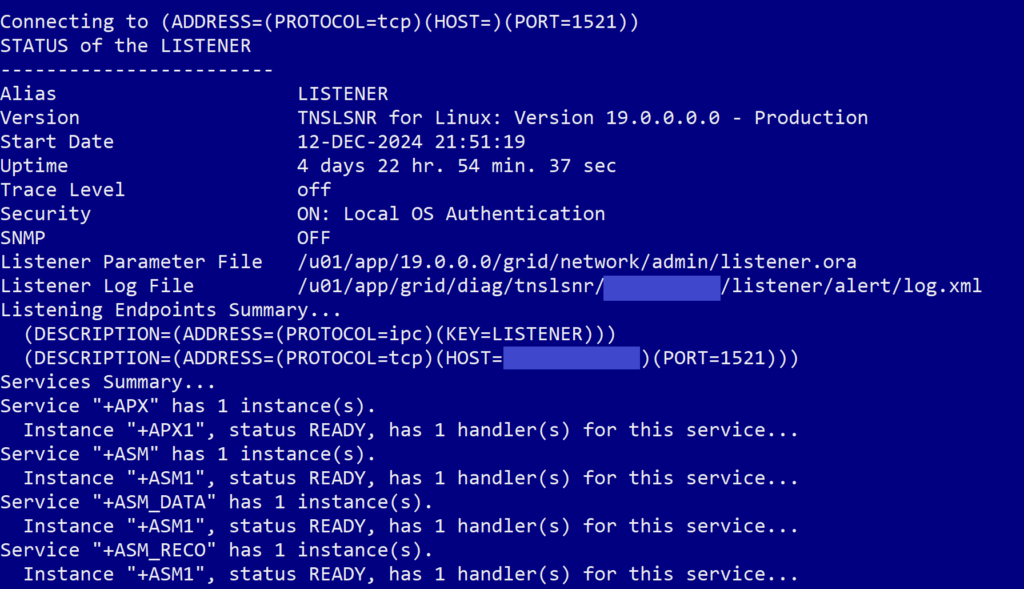
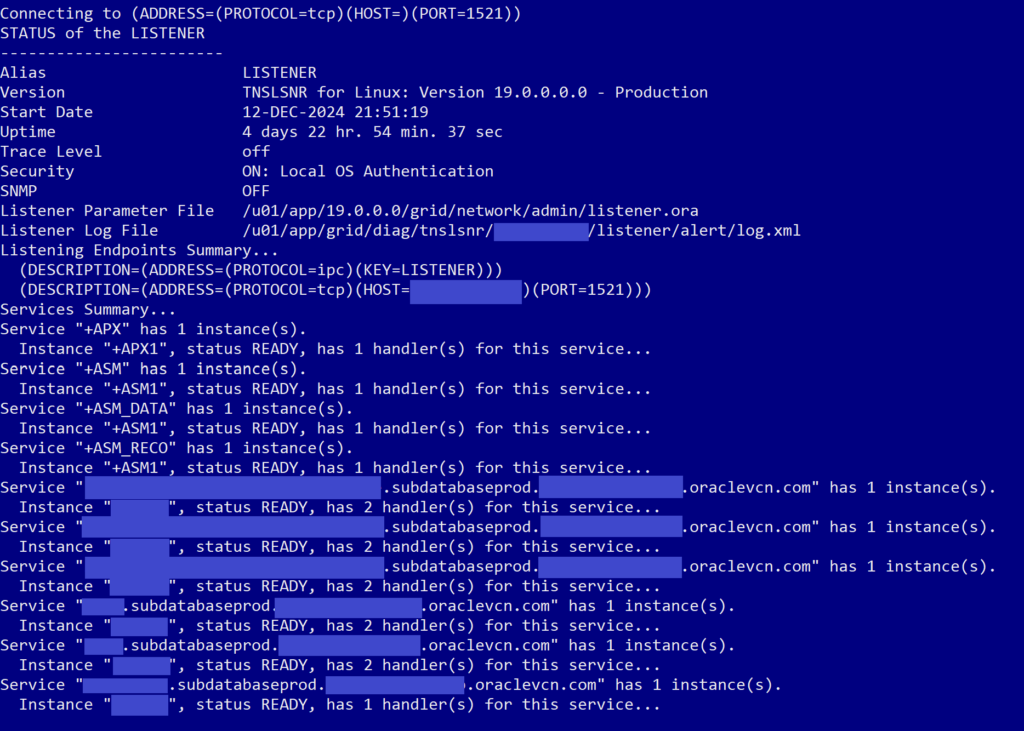
What we expected we would see was a whole list of listeners for our database and the pluggable databases on it, like this:
ps -ef | grep LIST
Will list out any file or directory on your server node that contains ‘LIST’, we used it to see what listeners may be on the node
How We Fixed the Problem
After running the lsnrctl status command I mentioned above and seeing that there were no listeners that it knew of for the whole database or the pluggable databases on it, we knew that there was clearly something wrong with how the listeners for the DBs came up (or rather didn’t) when the server patched. The first solution we attempted was a classic–reboot the machine to see if that would force the listener to come up how it should have. This did not resolve the problem for us, we still didn’t have a listener for the database.
To figure out the real solution, we of course hopped on Google, and I found this StackOverflow answer that mentioned the person had to update their tnsnames.ora file on the server to include the missing listener, and once they did that it fixed the issue.
Since my teammate had no other ideas to try, we opened the tnsnames.ora file on our server to see if there were any entries in it for the listener of the server we were on. Unfortunately, there was not an entry for the listener that should exist on the server, just listeners for other servers that we connect to. Based on the StackOverflow solution, we decided that we would manually enter the connection entry for the listener. But first we had to figure out what the correct name would be. To do that, we ran this command:
# Start a sqlplus session
sqlplus / as sysdba
# Run command to see the name of the listener that the database system is expecting
show parameter localThat gave us the following output:
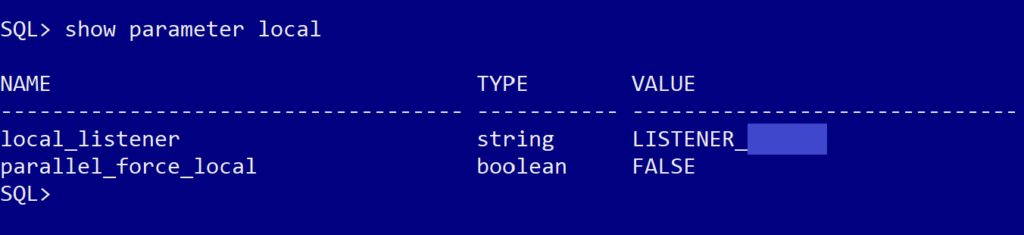
Based on that output above, the server was looking for a listener called “LISTENER_dbname”, so now we knew what to enter into the tnsnames file (with a little assistance from looking at what was in the same file but on the test server, so we could get the formatting correct).
Step by Step Solution to Update TNSNames.ora
- Navigate to the tnsnames.ora file location on the server:
cd /u01/app/oracle/product/19.0.0.0/dbhome_1/network/admin - Create a backup of the tnsnames file just in case you mess something up and need to revert:
cp -p tnsnames.ora tnsnamesbak.bak— that iscp -p <source file> <new file name> - Open the file using the “vi” editor:
vi tnsnames.ora(If you’re like me and not great with vi, use this cheat sheet I found online to help you use the editor) - Navigate to the end of the file (SHIFT + G)
- Press
Ito enter the Insert mode - Copy the text to setup your local listener into the file, making sure there are no leading spaces or extra spaces anywhere
LISTENER_DBNAME = (ADDRESS = (PROTOCOL = TCP)(HOST = <hostname>)(PORT = 1521))- The
LISTENER_DBNAMEis what we retrieved above with theshow parameter localcommand, theHOSTis the hostname of your instance which you can find in the console if you don’t know it already
- Save the file
- Press
ESCto exit Insert Mode SHIFT + ;to enter Command Mode so we can save and quitwqthenEnterto write and quit
- Press
- Now we must register the newly added listener with the system so it knows what to use. Enter a sqlplus session and run the following commands:
alter system register;: This command will register current settings at the container database levelalter session set container=<PDBName>;: Change your session into your first pluggable databasealter system register;: This command will now register current settings at the pluggable database level. Repeat this step and the previous one to register settings for each pluggable database on your system
- To validate that the change fixed the problem, run the
lsnrctl statuscommand again and see that you should now have multiple lines below the ASM listener lines, one for each container database and one for each pluggable database. Like this:
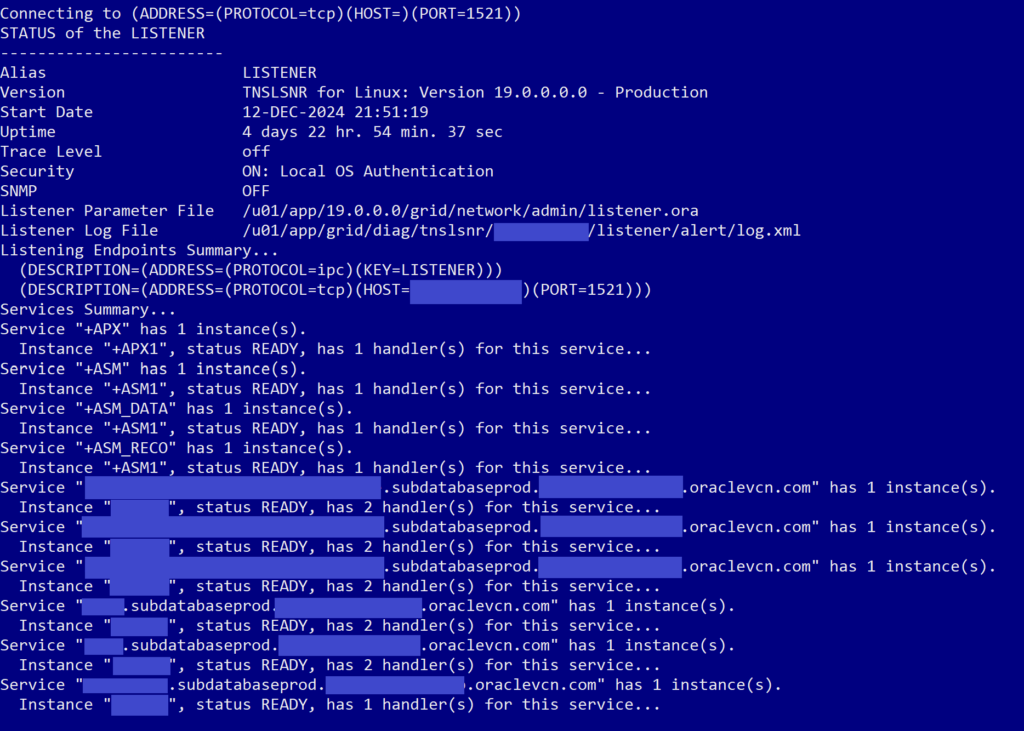
After we completed all the above steps, my app dev was able to connect his app to the database again and we were able to wrap up our very late working session. And thankfully I documented this all the day after, because we then had to patch a different production database on the weekend and ran into the exact same issue, and I was able to fix it in just a couple minutes this time. I don’t understand why test went flawlessly and then production had issues with the exact same patch, but such is life in the technology realm. Nothing ever behaves like you really want it to.
Summary
If you run into the error on your Oracle system that indicates the listener isn’t working or isn’t present, you should be able to follow the detailed steps I outlined above to get your database back in working order.
Did you run into something like this with the most recent Oracle database patches? If so, I would love to hear about your experiences down in the comments below.

