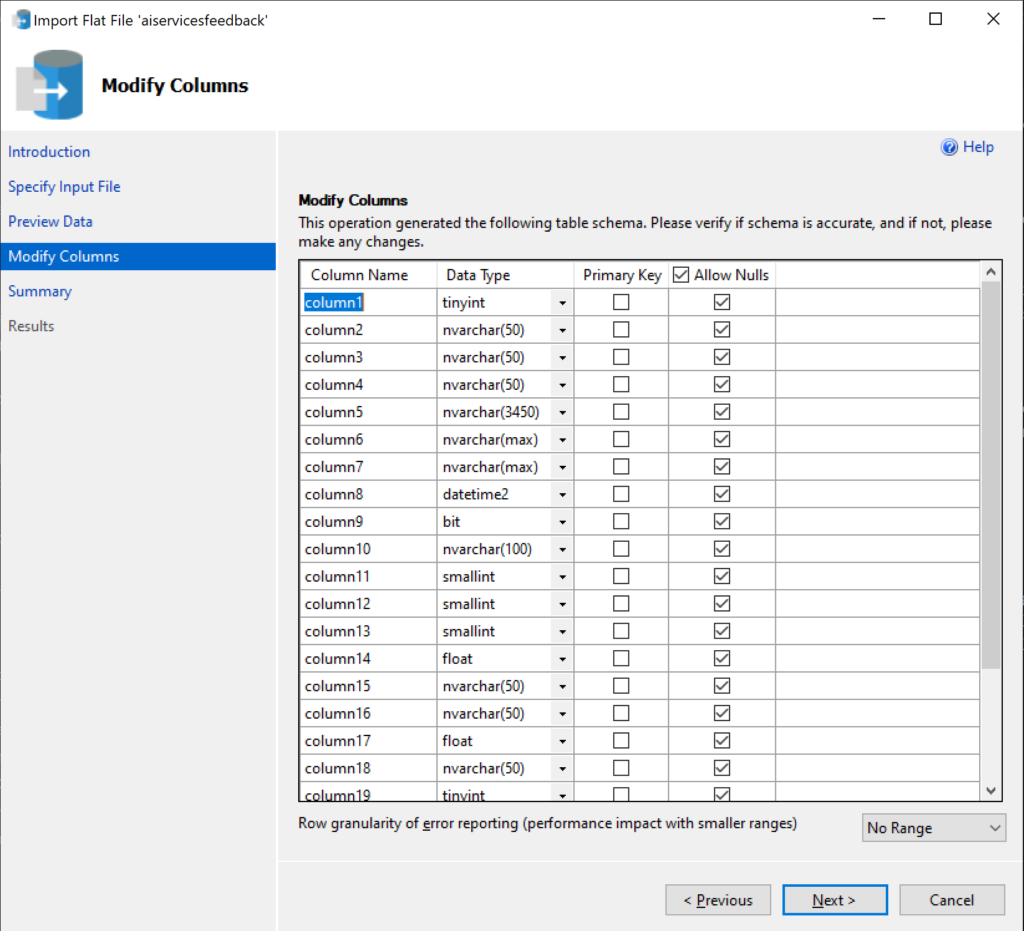
I am starting a multi-week series of posts covering the topic of Bicep, Microsoft’s Infrastructure as Code scripting language, since I have been working with this tool heavily for the past several months. You may wonder why a database developer is using Infrastructure as Code, since DevOps engineers typically do that. However, I decided to learn Bicep as a proof of concept for my team since we repeatedly find ourselves creating the same types of resources for our projects. We would like to reduce the amount of time and effort we put into creating our infrastructure so we can spend more time developing databases and pipelines to get our users the things they care about.
Stay tuned in the coming weeks for more details on how I have started integrating Bicep templates into my database development lifecycle.
What’s in this post
- What is Bicep?
- Use cases for Bicep
- What I use Bicep for
- My thoughts on Bicep
- Best resources for learning Bicep
- Summary
What is Bicep?

Bicep is a declarative scripting language created by Microsoft as a successor to and addition on top of their existing Azure Resource Manager (ARM) templates. (Yes, the new templating script language is called Bicep because the original was called ARM.) Bicep is a scripting language that allows you to easily and quickly write declarative scripts to define how you want Azure resources to be created. These scripts, called templates, are used for Infrastructure as Code, which means you are generating your infrastructure of cloud objects using code instead of provisioning them manually through a portal. The main competitor for Azure Bicep is Terraform, which is a multi-platform tool that essentially does the same thing. But Bicep is developed by Microsoft to work only with the Azure cloud, so it is better suited for deploying Azure resources than Terraform is.
After you have created your Bicep script defining the resources you want to deploy to your Azure cloud environment, you deploy that template either manually or through a pipeline, and Azure gets to work creating the specified resources. In the background, as the deployment begins, the first thing Azure Resource Manager does is convert the Bicep script into the traditional JSON script used by ARM templates, so that it can understand and process your requests, since Bicep is essentially a nicer skin built for ARM. Once the template has been converted to JSON, Azure Resource Manager starts parsing all resource requests and sending those to the correct ARM APIs to create those resources.
If your template is set up correctly, all your requested resources will deploy to your cloud environment, and the time it takes to deploy depends on the resources you are creating.
Use cases for Bicep
Bicep templates are great for any Azure cloud users who find themselves creating the same types of resources over and over again, or for anyone who wants to make their environment re-deployable. For example, if you need to recreate your development environment from production after each deployment cycle, you could write Bicep templates to do that work for you. Essentially, if you are doing resource deployment on a regular interval and you would like to stop doing all that work manually, to reduce human error or to make the process more efficient, Bicep may be the tool for you.
What I use Bicep for
I started using Bicep as a proof of concept for my team to determine if it would be suitable for our needs for creating Azure Infrastructure as a Service (IaaS) Windows servers which we install SQL Server on. As of the time I am writing this, I still haven’t figured out 100% how to generate those servers exactly as we need them through Bicep, but I’ve gotten a good way through writing a template to provision what we need. I have proven that Bicep will work for that, but there are some final technical needs, such as using a custom virtual machine (VM) image with SQL Server already installed with our required settings, which I haven’t quite figured out yet.
Another use case that I have completed a proof of concept for is to generate all required minimum resources for our Azure-based AI chatbots with one template, which has already been immensely useful for me and my team. Creating fully cloud-based resources with Bicep has proven to be much easier to accomplish than creating the IaaS servers I started with, because all specifications and settings for those resources are managed by Azure, so Bicep handles them easily. It took me only a single afternoon to write my AI chatbot backend Bicep template, whereas it took me over a week to get my IaaS Bicep template partially working.
This new AI backend template creates an Azure SQL Server, Azure SQL Database, firewall rules, key vault, key vault role assignment, storage account, auditing on the SQL Server, and a Search Service for managing the document indexes used by the bots we’re developing for our business users. When I was doing this all manually, it would take me about an hour to work through the portal and deploy each of these resources. But now that I’ve turned it all into a Bicep template, it takes only a few minutes to deploy it all.
My thoughts on Bicep

Overall, I think Bicep is a cool and useful tool to use to create your Azure resources using a single script, which can be deployed over and over again. It really speeds up the creation of resources and reduces the chance of manual error while clicking through the portal setup of the same objects. There are several flaws with how it operates, such as not always understanding the hierarchy and order of deployment required for related resources, like it claims to do easily, but that isn’t an insurmountable challenge.
As with most scripting or programming languages, I wish there was more and better documentation from Microsoft to help us newbies figure things out faster, but it’s not impossible to learn. I would recommend that anyone who is tired of manually deploying the same or similar Azure resources repeatedly look into using Bicep to speed up their infrastructure work.
Best resources for learning Bicep
I learned most of what I know about Bicep from a Microsoft Learn workshop that is free online. The first learning path I worked through was the Fundamentals of Bicep, which I would recommend for any developer who is new to Bicep. After I completed that one to get a general understanding of writing Bicep, I then completed a few separate modules from the intermediate and advanced Bicep learning paths. Then there were many things I just had to learn on my own through other resources outside of Microsoft or through my own trial and error.
Summary
Bicep is a great tool that all types of developers working in the Azure cloud can likely use to speed up their development lifecycles. If you’re interested in learning more about Bicep, stay tuned for the next few weeks as I take a deeper dive into how Bicep works using detailed real-world examples.