The other day I needed to verify that some IaaS (infrastructure as a service) SQL Servers (“SQL Server on Azure VMs” as Microsoft puts it) I created for a project a couple months ago were setup exactly as we want them to be before we move them to production in their upcoming upgrade. There were several things I needed to check to ensure the servers match our team’s standards, and one of them was double-checking to ensure that Entra ID authentication is enabled for the servers. I knew that we had worked through all the required steps on the Azure portal to enable that type of authentication, but wanted to validate to make sure I could login to the server with that authentication type. However, what I discovered is that I could not login with my Entra ID account despite Entra being enabled for the server. This was really confusing to me so I set out to figure out why it wasn’t behaving the way I thought it should be and why I could log in with Windows Authentication but not Entra MFA.
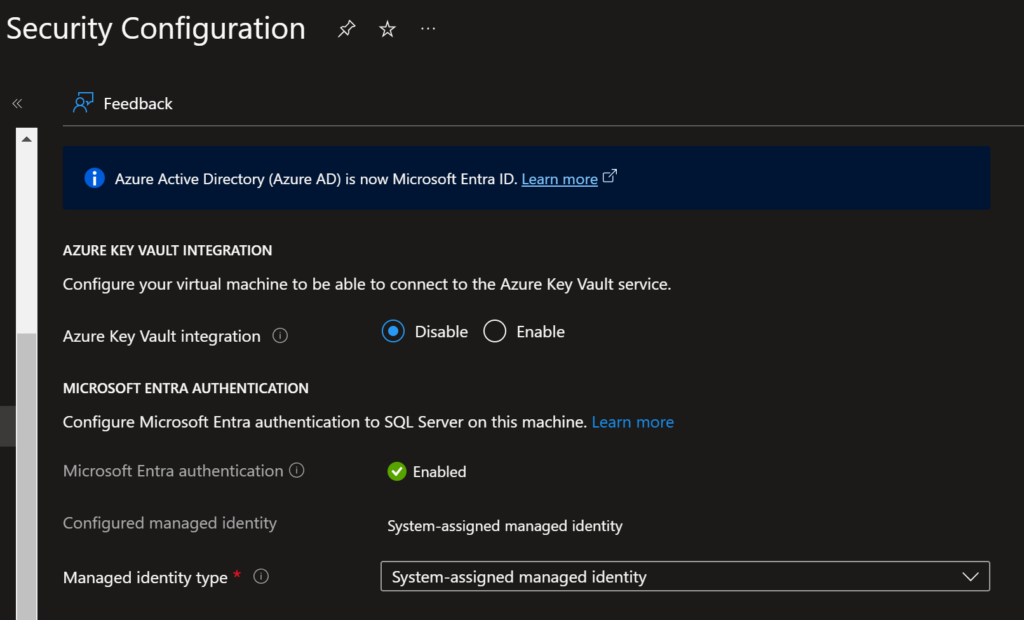
When I originally set up my servers a couple months ago at this point, I know that I fully went through the process in this Microsoft document to add Entra authentication to the SQL Server. But since it had been a couple months, I reviewed everything in the settings for the server and confirmed that it all should be set up to allow me to authenticate with my Entra user when connecting to the server through SSMS. This is what the security configuration page looked like for each of my servers, and it shows that Microsoft Entra Authentication is Enabled.
Based on that information, I thought that I should be able to login with Entra, yet I still couldn’t. The only way I could connect to the server was to use Windows Authentication. So what was the problem then?
What my problem was and how I solved it
The next step of my troubleshooting process was to login to the server and look at the groups I added for my team so that we can be the admins on the server. For some reason, we have two different groups so I needed to review both of them. What I found when reviewing the logins for our groups is that both were created using the FROM WINDOWS statement, since I had directly copied the logins from the old versions of our servers which were created before Entra authentication was possible for IaaS servers.
That was the problem! The logins for our groups, which are now in Entra ID and we want to use Entra auth to login with, were created as Windows logins which is why I could only login with Windows authentication. Makes a lot of sense.
To resolve this problem and make it so that I can login to the server with Entra instead, I had to drop and recreate the logins using the parameter FROM EXTERNAL PROVIDER, like this.
Once I made that change, I was then able to login to the server with Entra MFA authentication like I originally wanted. And since I had made multiple servers with this same issue, I had to go and make the same changes on those as well. Super easy to overlook when migrating logins from an older server to a new, but also super easy to fix.
How to tell at a glance if a login is Windows or Entra
There is a super quick way to tell at a glance on your server if a group login is an Entra based group or a Windows authentication based group, and that is to see what kind of icon is given to the login in the Object Explorer list. The icon for the Entra group looks the same as a single user icon, whereas the icon for the Windows group looks like multiple people in front of a server.
Summary
If you run into a situation where you enabled Entra ID authentication on your IaaS SQL Server instance in Azure yet you still can’t login to the server with Entra authentication, you may want to check to see what type of authentication your login was created with. If you want to be able to login through a user or group with Entra ID, you need to make sure that the login was created with the phrase FROM EXTERNAL PROVIDER instead of FROM WINDOWS.
Quick side note
This form of Entra authentication with IaaS servers in Azure is only available for SQL Server 2022. If you have older versions of SQL Server installed on Azure VMs, you will still need to use Windows authentication for your logins.
Before the holidays, I had the pleasure of doing the most recent round of patching for our production Oracle databases, to apply the patches that were released in late November. Similarly to how a lot of things behave unexpectedly in the IT world, I had different results of the patching in production compared to what happened in our test environments when I applied the same patches there first a few weeks before production. During the application of the patches in test, we had absolutely no issues, the patches applied seamlessly and it was super easy, although time consuming. Then in production, late at night on a Thursday evening when I should have been in bed already, the patches seemed to have been applied without issue again, except this time, my application developer teammates could not get their apps to connect to the database again once it came up.
When my app dev teammate tried to reconnect his app to the newly patched server, he received an error similar to the following:
ORA-12514: TNS:listener does not currently know of service requested in connect descriptor
Thankfully my teammate used to deal with Oracle databases directly himself so he could help me run commands to troubleshoot what the app was encountering. We were quickly able to see that things weren’t right, but also we weren’t quite sure how to fix them.
Helpful Commands
The following commands were ones that helped us figure out what was wrong with the database after it had been patched. I ran these through a terminal connection to the node using PowerShell.
lsnrctl status
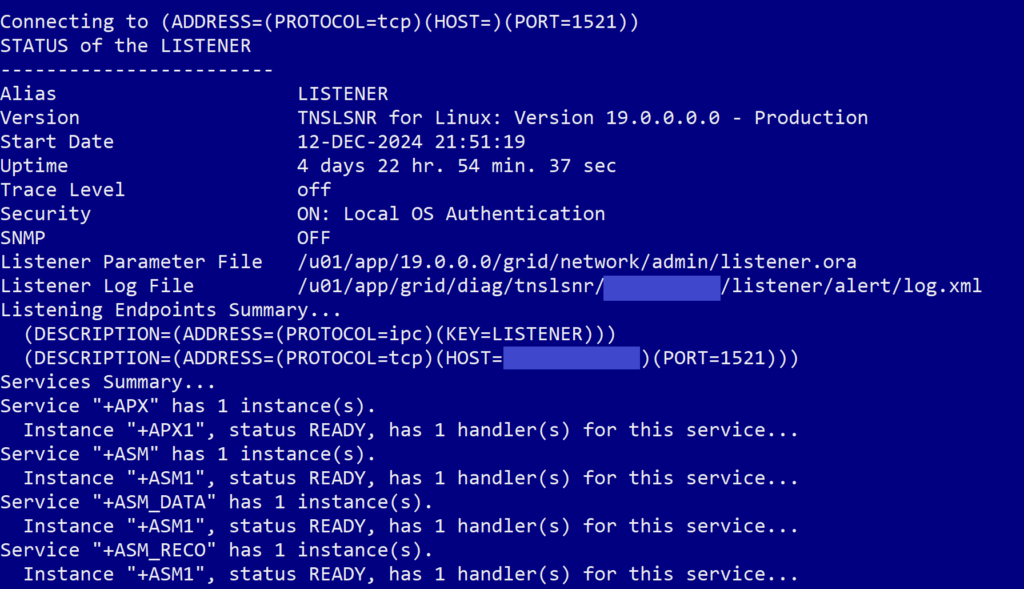
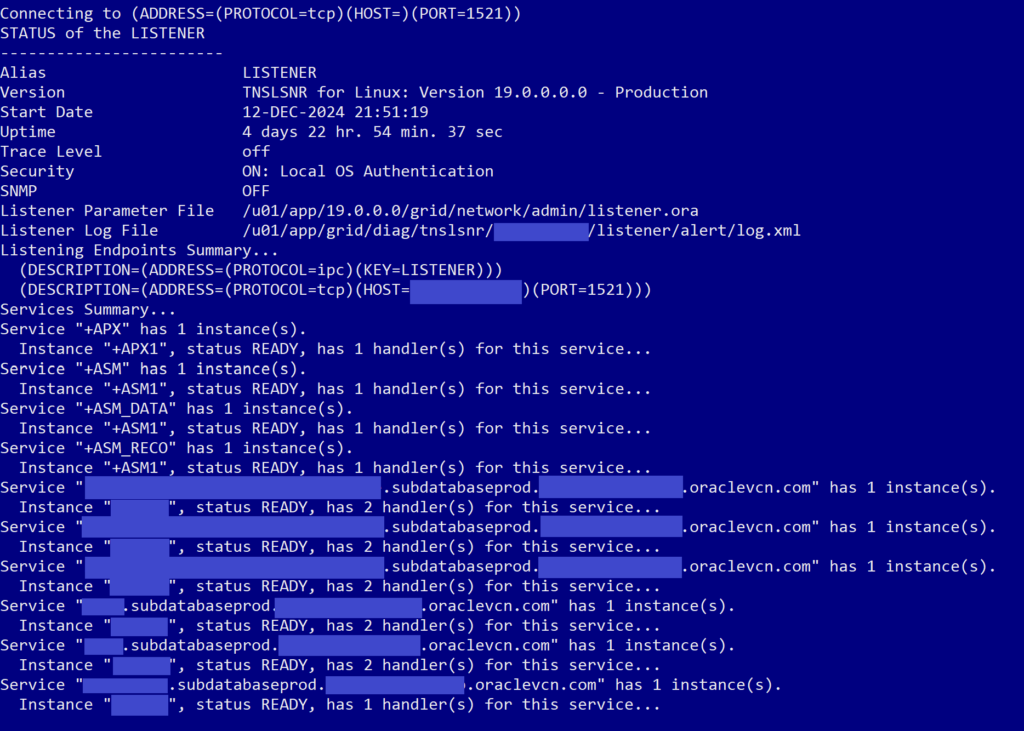
This command checks the current status of the listeners available on the system. When we ran the command, we got an output that looked like this, with status for a listener related to ASM but none of our container databases or pluggable databases:
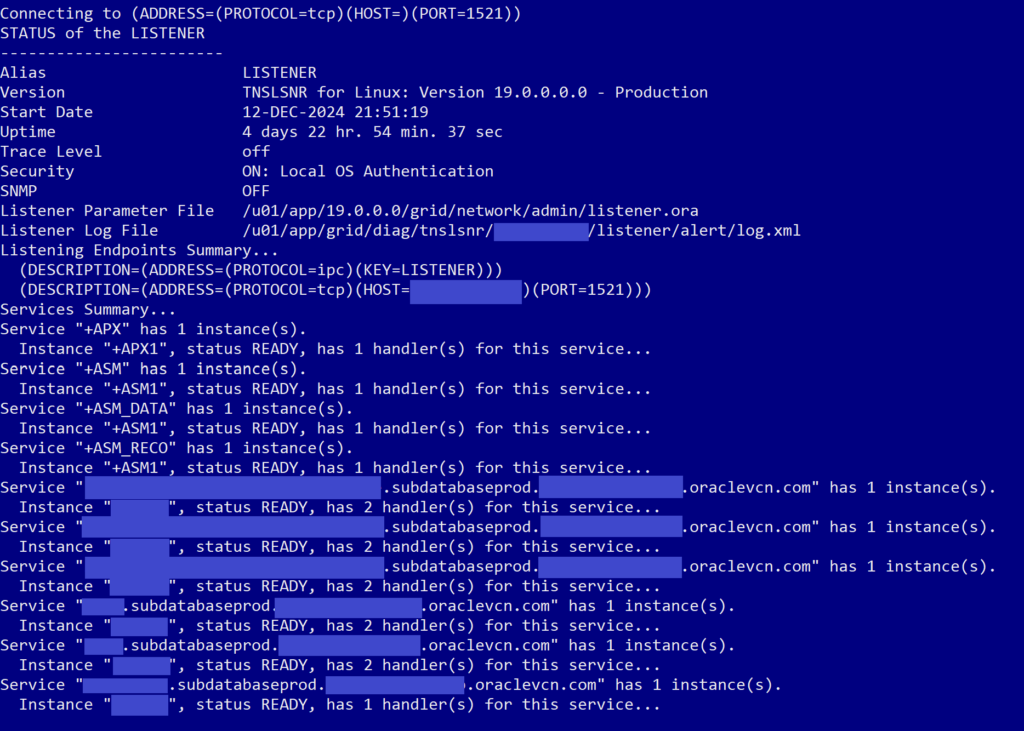
What we expected we would see was a whole list of listeners for our database and the pluggable databases on it, like this:
ps -ef | grep LIST
Will list out any file or directory on your server node that contains ‘LIST’, we used it to see what listeners may be on the node
How We Fixed the Problem
After running the lsnrctl status command I mentioned above and seeing that there were no listeners that it knew of for the whole database or the pluggable databases on it, we knew that there was clearly something wrong with how the listeners for the DBs came up (or rather didn’t) when the server patched. The first solution we attempted was a classic–reboot the machine to see if that would force the listener to come up how it should have. This did not resolve the problem for us, we still didn’t have a listener for the database.
To figure out the real solution, we of course hopped on Google, and I found this StackOverflow answer that mentioned the person had to update their tnsnames.ora file on the server to include the missing listener, and once they did that it fixed the issue.
Since my teammate had no other ideas to try, we opened the tnsnames.ora file on our server to see if there were any entries in it for the listener of the server we were on. Unfortunately, there was not an entry for the listener that should exist on the server, just listeners for other servers that we connect to. Based on the StackOverflow solution, we decided that we would manually enter the connection entry for the listener. But first we had to figure out what the correct name would be. To do that, we ran this command:
# Start a sqlplus session
sqlplus / as sysdba
# Run command to see the name of the listener that the database system is expecting
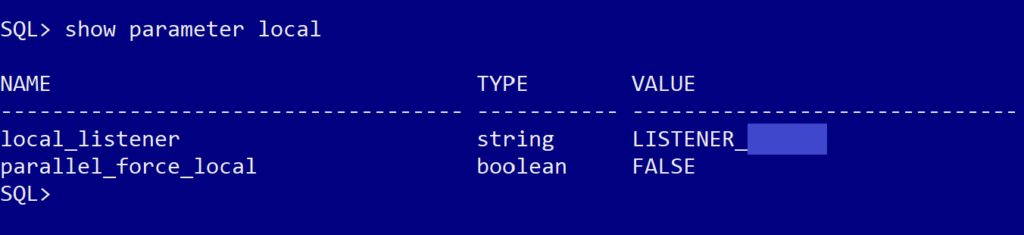
show parameter local
That gave us the following output:
Based on that output above, the server was looking for a listener called “LISTENER_dbname”, so now we knew what to enter into the tnsnames file (with a little assistance from looking at what was in the same file but on the test server, so we could get the formatting correct).
Step by Step Solution to Update TNSNames.ora
Navigate to the tnsnames.ora file location on the server: cd /u01/app/oracle/product/19.0.0.0/dbhome_1/network/admin
Create a backup of the tnsnames file just in case you mess something up and need to revert: cp -p tnsnames.ora tnsnamesbak.bak— that is cp -p <source file> <new file name>
Open the file using the “vi” editor: vi tnsnames.ora (If you’re like me and not great with vi, use this cheat sheet I found online to help you use the editor)
Navigate to the end of the file (SHIFT + G)
Press I to enter the Insert mode
Copy the text to setup your local listener into the file, making sure there are no leading spaces or extra spaces anywhere
The LISTENER_DBNAME is what we retrieved above with the show parameter local command, the HOST is the hostname of your instance which you can find in the console if you don’t know it already
Save the file
Press ESC to exit Insert Mode
SHIFT + ; to enter Command Mode so we can save and quit
wq then Enter to write and quit
Now we must register the newly added listener with the system so it knows what to use. Enter a sqlplus session and run the following commands:
alter system register;: This command will register current settings at the container database level
alter session set container=<PDBName>;: Change your session into your first pluggable database
alter system register;: This command will now register current settings at the pluggable database level. Repeat this step and the previous one to register settings for each pluggable database on your system
To validate that the change fixed the problem, run the lsnrctl status command again and see that you should now have multiple lines below the ASM listener lines, one for each container database and one for each pluggable database. Like this:
After we completed all the above steps, my app dev was able to connect his app to the database again and we were able to wrap up our very late working session. And thankfully I documented this all the day after, because we then had to patch a different production database on the weekend and ran into the exact same issue, and I was able to fix it in just a couple minutes this time. I don’t understand why test went flawlessly and then production had issues with the exact same patch, but such is life in the technology realm. Nothing ever behaves like you really want it to.
Summary
If you run into the error on your Oracle system that indicates the listener isn’t working or isn’t present, you should be able to follow the detailed steps I outlined above to get your database back in working order.
Did you run into something like this with the most recent Oracle database patches? If so, I would love to hear about your experiences down in the comments below.
During server upgrades and migration projects, you will likely run into the task or issue where you need to transfer the server logins from the previous to the new server. For non-SQL authenticated users, this is simple. But if your source server happens to have more than a handful of SQL Authentication users or you don’t have access to the passwords of those users, it would normally be very difficult to transfer those logins to the new server.
I recently setup three new test environments based on a current production environment, and there were literally dozens of SQL Authentication users on the production server that needed to be copied to the new environments. I didn’t have access to the passwords of any of those users so I couldn’t just recreate them manually. That is where two non-standard Microsoft stored procedures come in very handy to help migrate all these users.
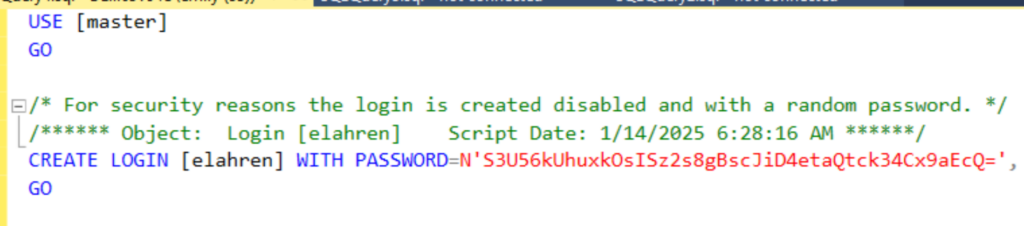
If you haven’t ever been challenged with this task before, copying SQL Authentication users from one server to another, you may not know why this can be a challenge, so I’ll describe that first. The problem with copying logins between servers is that unless you know the password of the account, just scripting out the login as a CREATE script will not give you the script that will recreate the login exactly how it is on the original server. For good reason, when you right-click on a login and opt to script it as a CREATE statement, SQL Server will generate the script but the password it puts in the script is a randomly generated string that isn’t what the true password is. So if you took that script and ran it on your new server, the login would be created, just with a different password than the login originally had, which could cause a lot of problems for whatever or whoever is using that login. (Side note: I don’t know if I’ve see this before, but when I scripted out my test login on my personal computer to demonstrate for this post, SSMS automatically added a comment saying the password is random, which is a helpful note there.)
The Helpful Stored Procedures
Given the above context of why transferring these logins isn’t as simple as scripting them on the source server and then running those scripts on the destination, how then are we supposed to accurately copy those logins to a new server? While there are some StackOverflow answers online that essentially provide a homegrown method of achieving the same goal, they all seemed overly complicated to me so I didn’t want to attempt them. And thankfully I found the Microsoft approved method online that very easily does all the required work for you.
To create the stored procedures that accurately script out all your SQL Authentication logins without generating any security issues or wrong password problems, go to this Microsoft document page. On that page, you’ll want to scroll down a bit until you see “Method 2” in the bulleted list, which is where you find the scripts to create the helpful stored procedures.
Note: For your own safety, please review the code before you run the script to ensure you know exactly what it’s doing and that it won’t cause issues for your specific system.
Copy the scripts from the web page into your SSMS new query window and then execute on the master database of the server you wish to copy logins from.
The script as it exists on the Microsoft website starts with the USE master command, but this will not work if you are trying to run the script on an Azure SQL Database, which no longer allows the USE statement to switch database contexts. If you are running the query on such a database, you will need to remove that top line and make sure yourself that you are running the command on the master database.
Scripting the Logins
Once you have executed the Microsoft script, there will now be two new stored procedures on your master database: dbo.sp_hexadecimal and dbo.sp_help_revlogin. The first one is used by the second, and you will only be executing the second procedure manually.
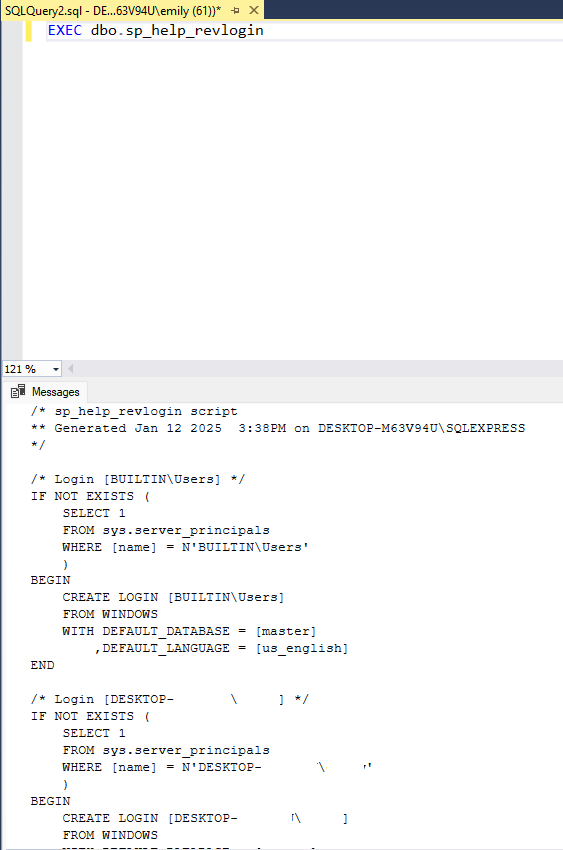
When you are ready to generate scripts to recreate all the logins on your server, you can execute the stored procedure dbo.sp_help_revlogin on the master database. Doing that will return data in the “Messages” tab of the results window with all necessary CREATE statements, including encrypted/hashed passwords, for your logins.
EXEC dbo.sp_help_revlogin
Reviewing the output further, I can see that the SQL Authentication users I have on my server have a “password” value displayed, which I can assure you is not the actual password I set for my users. Instead, the password value you see in the script is a securely hashed version of the password stored in the depths of the server security settings. The script has included the HASHED keyword at the end of the password which will notify the new server we are going to run this on that the password should be handled as the hashed value it is so the server doesn’t literally set the login password to the provided value.
Creating the New Logins
Copy the output presented in the “Messages” tab of your query window into a new query window with a connection to the server you want to add the logins to. Now to create all your logins from the original server, all you need to do is to execute the script. It’s as simple as that! You have now copied all your logins, including any login-level permissions they were assigned on the original server, added to your new server.
Summary
Copying SQL Authentication logins from one server to another doesn’t have to be a difficult or time-consuming process involving looking up old saved passwords or writing your own script to maybe fully copy the logins. Instead of trying to write a homegrown solution yourself, save yourself the time and effort and use the two stored procedures that Microsoft already wrote and shared to do the work for you.
This may seem crazy to some of you, but so far in my career I have been able to successfully avoid learning how to use the PIVOT feature of queries in SQL. Every example I ever came upon in code someone else wrote, I was able to get the gist of what was happening in the code without truly understanding what the query was doing. Until this week when I decided enough was enough and that writing a PIVOT query was going to be the easiest way to get the data I needed to check my work on project I am developing. This post won’t go into too much detail about writing complicated PIVOT queries, because the one I wrote wasn’t that complicated, all things considered. I mostly want to celebrate and share that I finally learned how to do something that I thought was going to be more difficult than it was.
The reason why I decided I needed to finally learn how to write a PIVOT query is that I am working on duplicating and automating a manual system a business user does every quarter to project sales data using a very complicated Excel spreadsheet. As I’m working on turning this spreadsheet into an automated system with SQL and Python (since we have the same data in a database just waiting to be used), I am constantly checking my queries and results against the source of truth that is the Excel spreadsheet.
This morning, I was tired of essentially having to PIVOT my data manually or in my head to check my work, so set about learning the PIVOT query structure.
The data in the spreadsheet looked something like this:
State
County
2020
2021
2022
2023
2024
ID
Ada
1000
1283
1476
1923
4657
ID
Canyon
54
55
65
76
87
ID
Boise
54
55
65
76
87
ID
Valley
54
55
65
76
87
But when I was querying the data from the database, the results of my SQL queries were looking more like this:
State
County
Year
Sales
ID
Ada
2020
1000
ID
Ada
2021
1283
ID
Ada
2022
1476
ID
Ada
2023
1923
ID
Ada
2024
4657
If it was actually that few rows of data, it wouldn’t be a problem, but I was needing to compare the data coming from my queries against what was in a spreadsheet that had over 3000 lines (there are so many more counties in the US than I ever would have guessed…). And I wanted to do the comparison using Excel so that I didn’t have to manually compare the spreadsheet data against my own, row-by-row. So in comes the pivot query to make my data look more like the data in the spreadsheet.
Writing the PIVOT Query
Learning how to write the query was more challenging than I expected because it seems like in the top results and examples online, even in the Microsoft docs, the queries are written in a confusing and non-intuitive way so I couldn’t figure out how to manipulate them to fit my own needs. The exception to this was this wonderful YouTube video by BeardedDev, which finally helped me figure out how to write my first pivot query that was actually what I needed it to be.
His video was so much more helpful than the written tutorials and docs that I looked through because he started out with the outline of what the query should contain, showed the general query he was starting with that he wanted to convert, then walked through step by step how to switch the original query into a PIVOTed query. I highly recommend watching that video. I don’t even want to try to explain it in my own words because he did it so well.
In the end, this ended up being the query I wrote which is exactly what I needed to make the formatting of my queries match what was already in the spreadsheet from the business user.
SELECT
[State], [County], [2020], [2021], [2022], [2023], [2024]
FROM
(
select [State], [County], YEAR, Sales
from dbo.HistoricSales
) AS Src
PIVOT
(
SUM(Sales)
FOR [YEAR] IN ([2020], [2021], [2022], [2023], [2024])
) AS Pvt
order by [State], [County]
Summary
Writing a PIVOT query in SQL isn’t super difficult if you are given the right examples and instructions. I highly recommend checking out BeardedDev’s video that I linked above for learning how to write a PIVOT query the easy way. That video is what finally helped me understand that type of query after working with SQL for over 6 years and not being able to understand it.
To keep resources secure in the Azure cloud environment, there are usually multiple levels of security that must be cleared for someone to be able to access a resource. For Azure SQL Databases, for example, the user who is trying to access the database must have access granted for their user account on the database but they also need to be given access for their IP address through the network firewall rules for the server or database resource.
I usually only need to add or update a single user’s firewall rule at a time when our business users get their IP addressed updated sporadically, but I had a situation last week where I needed to add over 40 firewall rules to an Azure SQL Server resource for a new database I imported on the server. I did not want to manually add that many firewall rules one at a time through the Azure Portal because that sounded tedious, boring, and like too many mouse clicks, so I instead figured out how to do it the fastest way possible–running a T-SQL script directly on the server or database through SQL Server Management Studio (SSMS).
Note: This would also work through Azure Data Studio or your chosen SQL Server IDE, I simply prefer to use SSMS so use that as a reference in comparison to completing the same actions directly through the Azure
According to this Microsoft document, it should be possible to grant firewall rule access for a user to a single database on a logical Azure SQL Server resource. In my experience in Azure so far, we’ve only ever granted firewall access at the server level instead, since that is acceptable for our business use-cases. But since it’s possible to set the same firewall rules at the database level according to Microsoft, I added how to do that to this post, as well as the server-level rules which I will be creating for my use case.
T-SQL for Creating Firewall Rules
Did you know it was possible to create both database-level and server-level firewall rules for an Azure SQL Database through SSMS using T-SQL commands? I didn’t before I started this project request last week. Going forward, I will likely use the T-SQL route through SSMS when needing to make multiple firewall rules instead of using the Azure portal, to save myself time, effort, and mouse clicks.
Create a Server-Level Firewall Rule
To create new firewall rules at the server level, you can connect to your Azure SQL Server through SSMS and run the following command on the master database.
/* EXECUTE sp_set_firewall_rule N'<Rule Name>','<Start IP Address>','<End IP address>'; */
EXECUTE sp_set_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4';
When you run that command, you are executing a built-in stored procedure that exists on the master database that will insert a new record for a server-level firewall rule into the table sys.firewall_rules, creating the server level firewall rule that will allow access through the specific IP address or IP address range. In the example above, I have the same value for both the Start IP Address and End IP Address parameters, but you can just as easily set that to a range of addresses, like 10.0.5.0 for the start and 10.0.5.255 as the end. I usually prefer to do that for a user’s IP address since our systems can change the last value fairly regularly, but since my current task was to grant access for servers, I set the start and end values to the same single IP address since I’m not expecting them to change frequently.
Create a Database-Level Firewall Rule
If instead of granting access to all databases on the server through a server-level firewall rule you would prefer to grant access to only a single database on your Azure SQL Server instance, you can do that as well. The T-SQL command to create a database-level firewall rule is the following. Notice how it’s very similar to the server-level command above, but with “database” specified in the stored procedure name.
/* EXECUTE sp_set_database_firewall_rule N'<Rule Name>','<Start IP Address>','<End IP address>'; */
EXECUTE sp_set_database_firewall_rule N'Example DB Rule','0.0.0.4','0.0.0.4';
The parameters that are required to run this database stored procedure are the same as what’s required for the server-level procedure, so you can either specify the same Start and End IP address values to allow access through a single address, or you can specify different values for the two to give access to a range of addresses. This procedure inserts records into the system table sys.database_firewall_rules on the database you ran the command on.
Speeding up the Creation of Execution Scripts
Knowing the above commands is helpful, and even works if you only have one or two firewall rules to add, but I promised I would tell you the fastest way possible to add 40+ firewall rules to a server, so how do I do that? How do I save myself the trouble of writing the above procedure execution commands 40+ times or copy/pasting/updating the line over and over again?
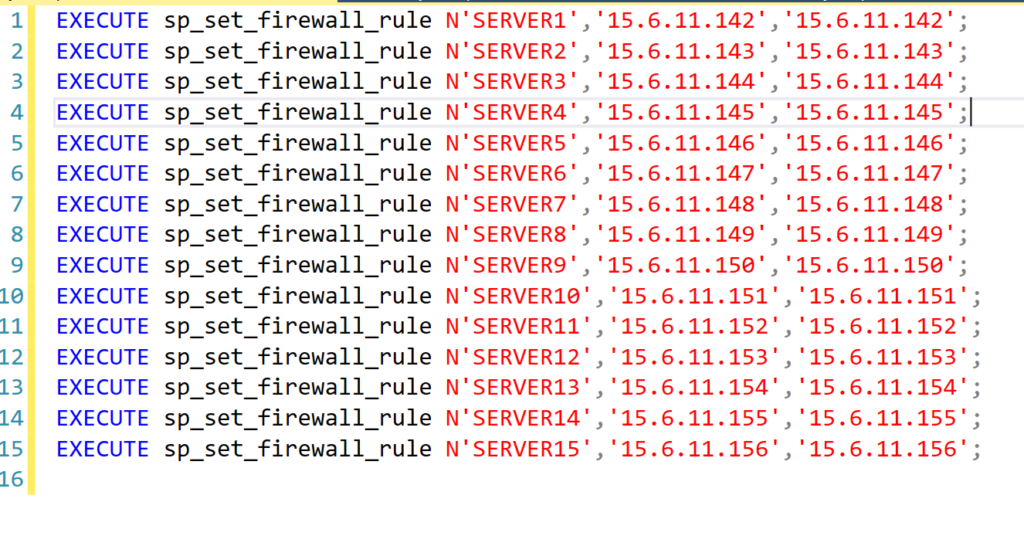
The trick I use is to generate my SQL queries in Excel, since Excel has the ability to concatenate strings and then to use the same formula across however many rows you have to generate the same concatenated string using multiple distinct values. I use this Excel trick quite frequently, whenever I need to generate the same type of SQL query/command multiple times based on specific values.
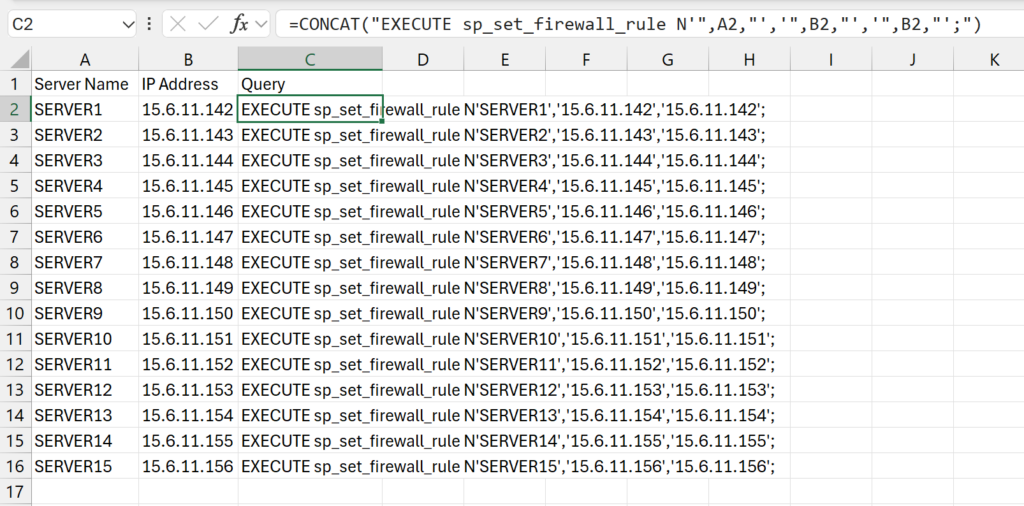
In this use case, I was provided a list of the names of the servers that needed inbound firewall access to my Azure SQL Database along with the IP addresses they would be using. I copied that information into two columns in Excel then wrote a formula in a third column to generate the SQL command that I needed to run to make a firewall rule for that particular server and IP address.
Here is an example of how I accomplish this type of task in Excel:
In Column A of the spreadsheet, I copied in the list of the server names I was provided. I am going to set the name of the firewall rule for each to the name of the server that is being given access. Column B then has the IP address that the server will be connecting through.
Note: all server names and IP addresses were made up for this example.
Then in Column C, I use the CONCAT function of Excel to generate the SQL query that I want, which I will then be able to copy to the database and execute to generate the firewall rule. The following is the full formula I used to generate the SQL command:
After I’ve successfully made the command as I want it for the first server in the list, I then copy that same formula down the column for every row to generate the same command for each server and IP address combination. Once all the queries have been created, I copy the entire Column C into an SSMS query window:
I then just have to click Execute and all the commands run, creating all the new firewall rules I needed in just a couple seconds. Believe me, this method of using Excel will save you a lot of time copying and pasting and updating IP addresses in the queries.
View existing Server-Level Firewall Rules Through SSMS
If you would like to review the list of server-level firewall rules that currently exist on your server, you can do so by running the following query on the master database of your Azure SQL Server instance.
select id, [name], start_ip_address, end_ip_address, create_date, modify_date
from sys.firewall_rules
order by id
This list will directly correspond to the list of values that you would see under “Networking” for your Azure SQL Server instance in the Azure portal.
View existing Database-Level Firewall Rules Through SSMS
If you would like to review the list of database-level firewall rules that currently exist on your database, you can do so by running the following query on the database you would like to see the firewall rules for.
select id, [name], start_ip_address, end_ip_address, create_date, modify_date
from sys.database_firewall_rules
As far as I am aware, there is no way to view this same list of details from the Azure portal, so this should be the source of truth for database-level firewall rules for an Azure SQL Database.
How to Delete Firewall Rules Through SSMS
Similarly to how there is a more efficient way to create multiple firewall rules through T-SQL queries in SSMS, you can also quickly delete a lot of firewall rules at once through SSMS using a delete procedure. I haven’t yet had to delete a large number of firewall rules at once, but you can follow the same process I outlined above for adding them, but use the deletion procedure instead.
Delete Server-Level Firewall Rules
The T-SQL command you can use to delete a specified server-level firewall rule through SSMS is:
EXEC sp_delete_firewall_rule N'SERVER1';
When deleting a rule, you only need to provide the name of the firewall rule you would like to delete.
Delete Database-Level Firewall Rules
The T-SQL command you can use to delete a specified database-level firewall rule through SSMS is:
EXEC sp_delete_database_firewall_rule N'SERVER1';
When deleting a rule, you only need to provide the name of the firewall rule you would like to delete.
Summary
In this post, I outlined the full process I used to generate 40+ server-level firewall rules on my Azure SQL Server instance as requested. Before starting on this task I had no idea that it was possible to generate these firewall rules through a T-SQL command in SSMS, I only knew about adding them through the Azure portal manually. But like every good programmer, I knew there had to be a better and faster way and I was correct. I hope this post helps save you a little time as well the next time you need to add more than a couple firewall rules to your server.
This is going to be a super quick post because I only want to share a short query that I’ve developed for myself to be able to see what schema-level permissions have been assigned to users on an Azure SQL Server. If you didn’t see my previous post about my least favorite things about Azure, you should check that out because it includes other queries I’ve been using to identify what permissions have been granted on a server or database.
The Query
My query I use for getting a list of all schema-level permissions on a database uses the sys.database_principals, sys.database_permissions, and sys.schemas views.
SELECT DISTINCT pr.principal_id, pr.[name], pr.[type_desc],
pr.[authentication_type_desc], pe.[state_desc], pe.[permission_name], pe.class_desc, s.[name]
FROM sys.database_principals AS pr
INNER JOIN sys.database_permissions AS pe
ON pe.grantee_principal_id = pr.principal_id
INNER JOIN sys.schemas as s
on s.schema_id = pe.major_id
ORDER BY pr.name;
As you can see, the query is very short but it provides the most useful and relevant information for schema-level permissions on a database. It provides just enough information without being overly complicated or giving you more than you need. This query tells me what users have been given what type of permissions for every schema in my database.
I have been working with Git for the last several years, but in my current position, I am having to do more of the manual work with Git to ensure my commits meet our branch policies when pushing, since my current company has stricter rules on the pipelines. One of the Git activities I’ve found myself doing nearly every week now is to Squash my commits. While initially learning how to do this, I found some resources online that were somewhat helpful, but as with most documentation, it seems the authors assumed some level of basic understanding of Git that I did not possess. I understand it now that I’ve been doing it so frequently, but want to make a concise post about how to squash commits with Git Bash.
To squash commits means to combine multiple commits into a single commit after the fact. When I code, I do commits every so often as “save points” for myself in case I royally screw something up (which I do frequently) and really want to go back to a clean and working point in my code. Then when it comes time to push to our remote repos, I sometimes have 5+ commits for my changes, but my team has decided that they only want to have squashed commits instead of having all that commit history that probably wouldn’t be useful to anyone after the code has been merged. That is when I need to combine and squash all my commits into a single commit. Squashing is also useful for me because while I am testing my code, I copy any necessary secrets and IDs directly into my code and remove them before pushing, but those IDs are still saved in the commit history so our repos won’t even let me push while that history is there. And squshing the old commits into a single new commit removes that bad history and allows me to push.
How to squash multiple commits
For the purpose of this post, assume I am working with a commit history that looks like this:
613f149 (HEAD -> my_working_branch) Added better formatting to the output
e1f0a67 Added functionality to get the Admin for the server
9eb29fa (origin/main, origin/HEAD, main) Adding Azure role assgmts & display name for DB users
The commit with ID 9eb29fa is the most recently commit on the remote. The two commits above are the ones I created while I was making my code changes, but I need to squash those two into one so that I can push to our remote repo. To do this, I will run the following Git command:
git rebase -i HEAD~2
That command indicates that I want to rebase the two commits before HEAD. And the -i indicates that we want to rebase in interactive mode, which will allow us to make changes to commit messages in a text editor while rebasing. When I run the command, Git opens Notepad++ (which is the text editor I specified for Git Bash) with a document that looks like this:
pick e1f0a67 Added functionality to get the Entra Admin for the server
pick 613f149 Added better formatting to the output
# Rebase 9eb29fa..613f149 onto 9eb29fa (2 commands)
#
# Commands:
# p, pick <commit> = use commit
# r, reword <commit> = use commit, but edit the commit message
# e, edit <commit> = use commit, but stop for amending
# s, squash <commit> = use commit, but meld into previous commit
# f, fixup [-C | -c] <commit> = like "squash" but keep only the previous
# commit's log message, unless -C is used, in which case
# keep only this commit's message; -c is same as -C but
# opens the editor
# x, exec <command> = run command (the rest of the line) using shell
# b, break = stop here (continue rebase later with 'git rebase --continue')
# d, drop <commit> = remove commit
# l, label <label> = label current HEAD with a name
# t, reset <label> = reset HEAD to a label
# m, merge [-C <commit> | -c <commit>] <label> [# <oneline>]
# create a merge commit using the original merge commit's
# message (or the oneline, if no original merge commit was
# specified); use -c <commit> to reword the commit message
# u, update-ref <ref> = track a placeholder for the <ref> to be updated
# to this position in the new commits. The <ref> is
# updated at the end of the rebase
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
The first comment in the document # Rebase 9eb29fa..613f149 onto 9eb29fa (2 commands) gives an overview of what the command is doing. We’re rebasing the three listed commits onto the most recent commits that’s on the remote, which will give us one new commit after that remote commit in the place of the two we currently have.
To rebase these commits, I will change the top two lines of that document to:
pick e1f0a67 Added functionality to get the Entra Admin for the server
squash 613f149 Added better formatting to the output
No matter how many commits you are squashing, you always want to leave the command for the first command in the list as “pick” and then every other commit needs to be changed to “squash”. Once you have made that change, save the file and close it. Once you close that document, it will open another text document containing the previous commit messages, giving you an opportunity to amend them. This is what my commit messages look like when the document pops up:
# This is a combination of 2 commits.
# This is the 1st commit message:
Added functionality to get the Entra Admin for the server
# This is the commit message #2:
Added better formatting to the output
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Fri Jul 12 11:11:10 2024 -0600
#
# interactive rebase in progress; onto 9eb29fa
# Last commands done (2 commands done):
# pick e1f0a67 Added functionality to get the Entra Admin for the server
# squash 613f149 Added better formatting to the output
# No commands remaining.
# You are currently rebasing branch 'my_working_branch' on '9eb29fa'.
#
# Changes to be committed:
# modified: file1.py
# modified: file2.py
# new file: file3.py
#
I will change the file to the following so that I have a single, concise commit message (although I would make it more detailed in real commits):
Updated the files to contain the new auditing functionality.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
#
# Date: Fri Jul 12 11:11:10 2024 -0600
#
# interactive rebase in progress; onto 9eb29fa
# Last commands done (2 commands done):
# pick e1f0a67 Added functionality to get the Entra Admin for the server
# squash 613f149 Added better formatting to the output
# No commands remaining.
# You are currently rebasing branch 'my_working_branch' on '9eb29fa'.
#
# Changes to be committed:
# modified: file1.py
# modified: file2.py
# new file: file3.py
#
Once you’ve updated your commit messages as you would like, save and close the file and then push the changes like you normally would. If you would like to confirm and review your changed commits, you can use git log --oneline to see that the log now reflects your squashed commit instead of what it had previously.
Note: One important standard of doing rebasing with Git is that you should not rebase changes that have already been pushed to a public or remote repo that others are using. It’s bad practice with Git to try to rewrite shared history, since keeping that history is the whole point of Git and version control. Try to stick to the custom of only doing rebasing with your own local changes.
Summary
In this post, I covered the basics of how to perform a squash commit of multiple commits using Git Bash. If this tutorial helped you, please let me know in the comments below. If you would like to read more of the details about what rebasing means, please refer to the Git documentation.
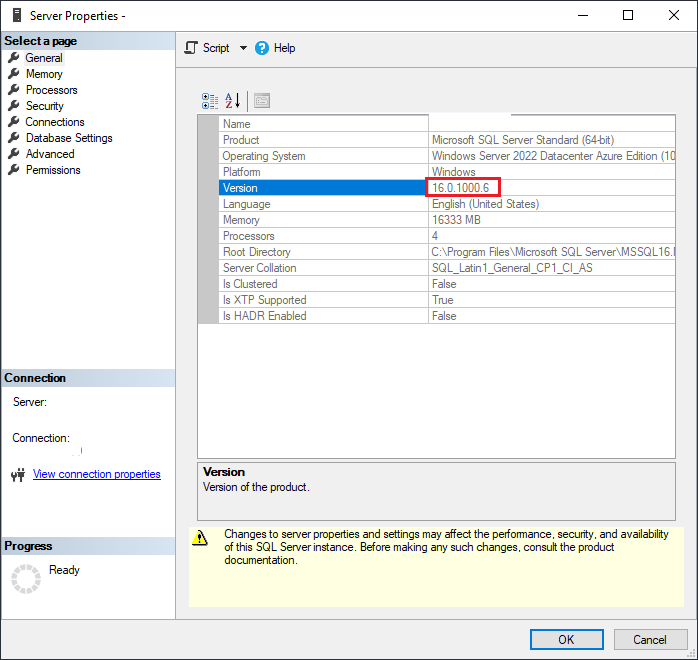
If you connect to a SQL Server instance using SSMS and you’re trying to find what version of of SQL Server it is, you might be left scratching your head since it doesn’t seem to be in the server properties anywhere. Or at least there isn’t a value that lines up with the version numbers you’re used to hearing (2016, 2019, 2022, etc.). This will be a quick and easy post explaining how you can find the normal version name for a SQL Server you’re connected to.
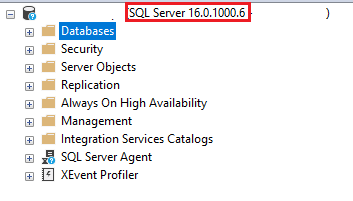
The first thing you need to do is connect to your server instance using SQL Server Management Studio (SSMS). After you connect, you should see the server listed in the Object Explorer, which is where we will be getting the version number from. To the right of the server name in paratheses, you should see something like “(SQL Server 16.0.1000.6 – myusername)”.
That is technically the most correct version number for the SQL Server software you are running, but it’s not the one that most people think of when they think of SQL Server versions. To get to that version, you can look at the very useful table included on this blog post from SQL Server Builds.
For the example screenshot above, the server is really SQL Server 2022 because the “Release To Manufacturing” number of “16.0.100.6” corresponds to that version of SQL Server, as can be seen in the table included in that blog.
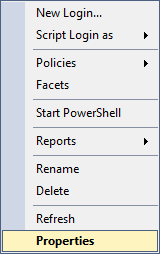
You can also find the same version number by right-clicking on the server in the Object Explorer list, then selecting “Properties” which will bring up a dialog where you can see the version and other settings for the server.
Note: For even more ways that you can find the version number of any SQL Server, there is this very useful blog post from SQL Server Builds again that I found super informative.
Summary
Now you should know how you can find the normal SQL Server version number for your instance based on the “Release to Manufacturing” number you will find to the right of the server name in the Object Explorer of SSMS. I wish they would put “SQL Server 2022” somewhere in the Properties of the server so we didn’t have to do this lookup, but for now we aren’t that lucky.
Note: Curious about what “Release to Manufacturing” really means? I found a great explanation on Wikipedia that clarified that term for me.
Have you ever wondered what the normal work tasks of a database developer/integration engineer looks like? If you have, then this is the post for you. This is a new series of posts where I simply give an overview of what I accomplished each week, giving insight into what life as a database developer looks like for those who might be curious. I also want to do these reviews for my own records and edification, because it’s always good to keep track of the things you accomplish at your job. This post is going to review the week of October 7 – October 10.
The week started with a request from one of my teammates to set up SQL Server 2022 on another Windows Server virtual machine as part of my ongoing project I am a part of. I have somehow made myself the SQL Server 2022 installation guru, so I’m not surprised that I was requested to complete this task.
Setting up the SQL Server itself was as easy as it could be, easier than the last few I did since the application using the server had less configuration requirements. But after installing the server and making sure the firewall rules were in place (as I learned two weeks ago), I then learned even more setup that I had missed previously that needed to be done for the server. The new thing I had missed was getting Entra ID authentication to work with the server, so one of my teammates showed me how to do that so that the new server was now setup perfectly.
Production Upgrade for an Application
My biggest feat of the week was having to do the production upgrade for the legal application project I’m on completely by myself. I was on this project with one of my teammates, but he had to be out this week for personal matters so I was left as the sole developer working on the production upgrade we had been building up to for months. Although I was nervous about being the only one responsible if something went wrong, I stepped into the challenge and completed the upgrade. I did run into a few issues during the upgrade process, but I was able to work them out by the end of the day by working with the vendor of the application, so I have to say the upgrade went pretty dang well given the circumstances. Pat on the back to me for surviving my first solo production upgrade.
Preparing for the Next Application Upgrade
I couldn’t celebrate this week’s successful application upgrade for too long, because I already had to be starting on the steps for the next phase of this application’s upgrade process. Thankfully, this week’s work for that next phase was only to take backups of two databases and provide that to the application vendor, so I wasn’t overly burdened with work for this part.
Writing Documentation about the Application
After completing that production upgrade, facing a few issues along the way, I knew that I needed to write everything down that I knew about the application and what went wrong with the upgrade, or else me and my team might forget the important but small details. None of us think that this type of work is truly something that we as database developers should be doing, we’re not application developers, but we have been told that we need to support this application from front to back so that is what we’re going to do. And since the territory is unfamiliar to everyone on my team, I know good documentation will be essential to continuing to support this application in the future.
Met with Colleague to Review Conference
There are only two women on my team: me and one other woman. We both attended the Women & Leadership conference two weeks ago so wanted to catch up with each other to review our learnings and takeaways so that we can present those ideas to our manager. This conversation was really lovely. When working in a field that is 98% men like I am, it’s always a breath of fresh air to be able to sit down, relax, and catch up with other women dealing similar tasks and issues. Our scheduled half-hour meeting turned into an hour because we were having a good time and brainstorming good ideas to present to our manager. We left with a list of items we wanted to cover with him and a plan for how to get some of his time to present our list.
Presented new Database Architecture to Division IT Team
I need to be forward and say that I was not the one who presented the database architecture to the other team, but I was included in the meeting since my teammate who normally works with this other team is going to be out of office for two months at the end of the year and I need to be apprised of the work he normally does.
This meeting with a business division IT team (not the corporate IT team that I’m on) turned out to be a fantastic relearning opportunity for me to see the database architecture possibilities in Azure. The backstory is that this other team had requested we create them a new database they could use for reporting purposes to not bog down their main application database. My teammate who normally works with them came up with several different new architecture possibilites that would fulfill the request, and ran those possibilities by the team to see which they would be most comfortable with. I had technically learned this same architecture information shortly after I started at the company, but that time is honestly a blur so I appreciated getting to see this information re-explained. I took lots of notes in this meeting and now feel more confident about making similar presentations and architecture decisions in the future when that will eventually be required of me.
Summary
This was a shorter week for me because I took Friday off, but I still accomplished a lot of big projects. I am looking forward to having some calmer weeks in the future where not everything is a “big stressful thing”, but I do appreciate that this week taught me a lot and helped me grow as a developer. I am slowly easing into the point of my career where I can start to be a leader instead of a follower, so I am taking each and every learning opportunity as a gift helping me to grow into that future leader.
Do you have any questions about what a database developer does day-to-day that I haven’t answered yet? Let me know in the comments below!
Now that I have been working in the Azure cloud environment for a few months with my new job, I have come to the realization that there is one thing related to Azure SQL Server instances that annoys me more than anything else in the Azure environment. Obviously every cloud environment is going to have its pros and cons, so this is only one small problem from the whole ecosystem. Azure has a lot of nice things to work with, so this complaint is very superficial, but I know others at my company have been confused by this issue so thought I would share the annoying difference here for educational purposes.
On-Prem SQL Server Permissions
The one thing that has been driving me crazy about Azure SQL Server instances recently is that there is not an easy way to quickly get an overview of the permissions a user/account/group has on the server and database.
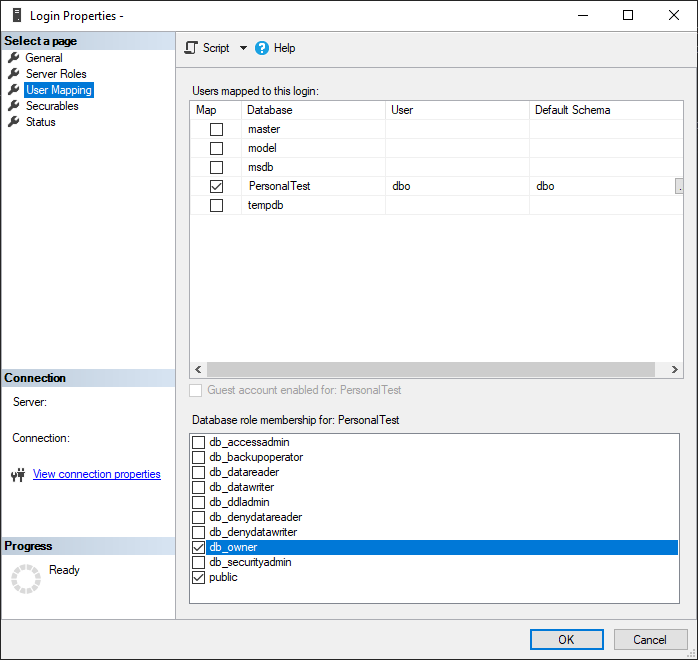
In on-prem/normal versions of SQL Server, you can open the “Security” section of the server or database then right-click on the user or group you want to review the permissions for, and then you’ll get a GUI that quickly shows all the server- or database-level permissions that user has. The following screenshot shows the Server Roles for a given login on my local test server, so you can quickly know what permissions the login has.
And then if you go to the “User Mapping” page of the Login properties, you can see any databases the login has access to as well as the permissions that user has on the database.
I love this interface that I’m pretty sure has been around for decades. It’s so much easier to view and quickly change the permissions for a login/database user that new new system in Azure-based servers.
Azure SQL Server Permissions
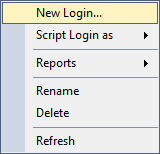
In comparison, you can’t easily view or determine the server- or database-level permissions any login or user has on an Azure-based SQL Server. You can’t even view any general properties of the user like you can for on-prem installations. For example, here is a screenshot of what you see on an Azure SQL Server when you right-click a Login from the Object Explorer:
If you do the same thing on the on-prem SQL Server, you can see that there’s an option to view the properties of the user, which will get you to the menus where you can see server- and database-level permissions, along with other properties as well.
If you can’t get a nice GUI representation of those login permissions, how are you supposed to know what permissions anyone has on your server or database? A SQL query.
While that kind of makes sense for a platform where you do most of your work with SQL, it does mean you need to do more work to write or track down a copy of the appropriate SQL query to get the necessary data, instead of to right-clicking on an object and have its information displayed to you immediately. The SQL query you need to get permissions information is also tedious to me because you can only do it for a single database at a time instead of being able to quickly view the permissions for every database on the server in one place. For example, if you have 3 databases on your server, you need to run the query individually for each of those databases. You can’t even utilize the “USE [database]” statement to quickly switch between the databases and get all the results in a single result pane (if you want to read more about that, I have another upcoming post to discuss that topic).
This is the query I use to review database permissions:
SELECT DISTINCT pr.principal_id, pr.[name], pr.[type_desc],
pr.[authentication_type_desc], pe.[state_desc], pe.[permission_name]
FROM sys.database_principals AS pr
JOIN sys.database_permissions AS pe
ON pe.grantee_principal_id = pr.principal_id
ORDER BY pr.name;
If you want to view the permissions at the server level, run that query on the master database. Then to view the permissions specific to a single database, you will need to switch to that database (using the database dropdown from the toolbar above the query window, or updating your full server connection to specify the other database).
To view the role assignments for users in your database, you can use the following query, which utilizes the views sys.database_permissions, sys.database_principals, and sys.database_role_members to gather all the useful information related to role assignments.
SELECT u.[name] AS [UserName],
r.[name] AS RoleName
FROM sys.database_principals u
JOIN sys.database_role_members drm ON u.principal_id = drm.member_principal_id
JOIN sys.database_principals r ON drm.role_principal_id = r.principal_id
WHERE u.[name] = N'TestUser';
Summary
While it’s not hard to get all role assignments and assigned permissions for logins and database users in Azure SQL Server instances, it isn’t as easy as it used to be with on-prem servers. I don’t think the new method of getting the permissions gets the information you need in as useful a way as the old method of using the GUI. I personally don’t prefer having to scroll through a table of information about each user and deciphering the details of their permissions, but I will continue to deal with it since that’s the only option for Azure SQL Servers currently.