In last week’s post, I covered the initial setup steps you must follow when starting to work with Liquibase. In this week’s post, I will be finishing up my tutorial of getting started with Liquibase. If you haven’t yet downloaded and set up Liquibase on your computer, please review that post before reading this one.
What’s in this post:
- Create the baseline changelog file for your database
- Adding and tracking ongoing database changes
- Structuring your changelogs according to best practices
- Outstanding questions
- Summary
Create the baseline changelog file for your database
Using the command “generate-changelog” with the CLI for Liquibase, we can create a SQL file containing queries that will regenerate all objects in your database. What database objects get scripted into this files depends on which license you have for Liquibase. If you have the open-source version of the tool, it will script out all non-programmable objects like tables, keys, etc. If you want or need to script out all of your programmable objects such as procedures and functions (plus other items), you will need to have the Pro version of the tool.
Either way, the command for creating the script is exactly the same.
“liquibase generate-changelog --changelog-file=mydatabase-changelog.sql --overwrite-output-file=true”
Let’s break this command down. The first two words are simple, you’re calling Liquibase and specifying you want it to run the generate-changelog command. The next part is the “changelog-file” argument that allows you to specify the file you want to write the new changelog to. The next argument, “overwrite-output-file” tells the tool if you want to overwrite that specified file if it already exists. In this case, I specified true for that argument because I want the tool to overwrite the example changesets in the file it created upon project creation with the actual queries for my database. After running this command, you should get a success message like the following.
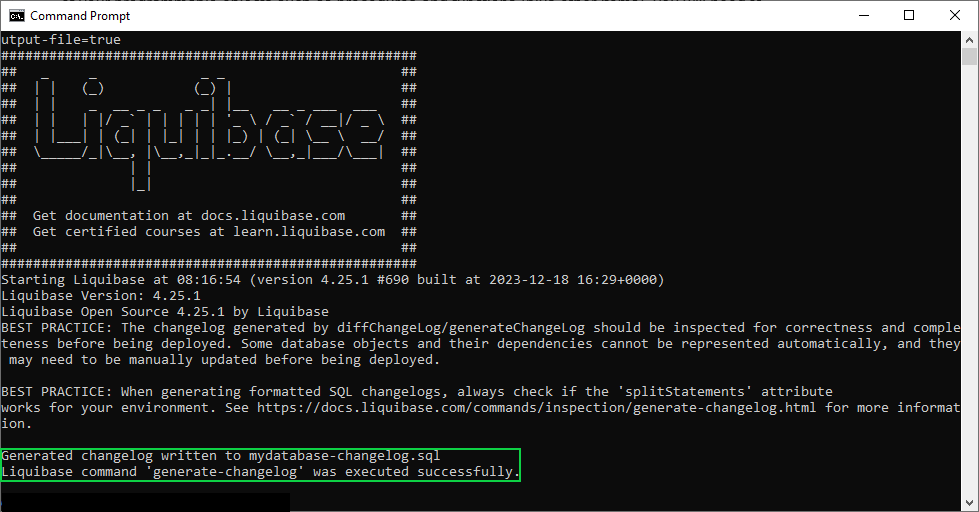
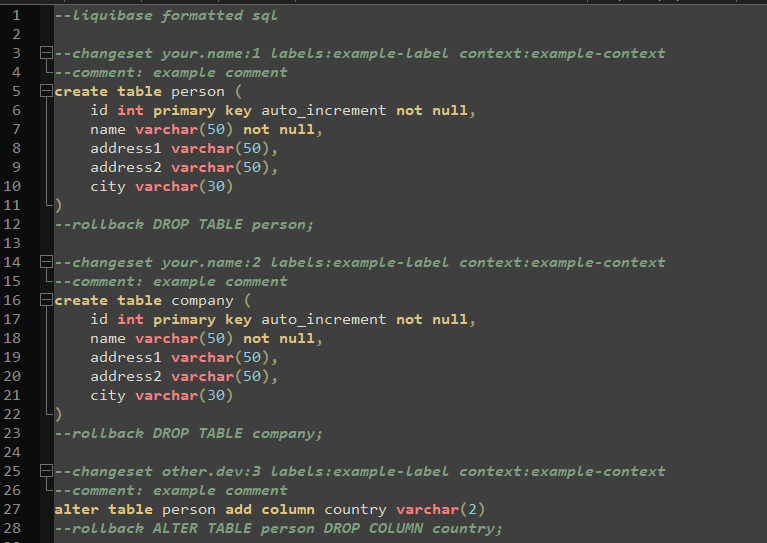
And if you open that specified file now, it should contain the actual scripts to generate all of the objects in your database, each change separated into its own changeset. Each generated changeset will be defined with the username of the person who generated the file, as well as the tracking/version number for the set.
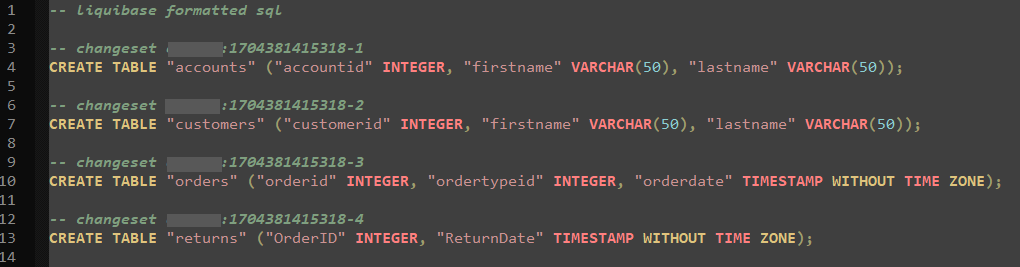
Now you are ready to start doing normal development and changes to your database because you have baselined your project.
Adding and tracking ongoing database changes
There are two methods for adding/tracking database changes with this tool: 1) add your scripts to the changelog file as changesets, then “update” the database with those changes, or 2) make your changes within the IDE for your database (ex: PGAdmin) then use the “generate-changelog” command to identify and script those changes.
Method 1: Adding Scripts to Changelog File
Open your changelog file and add a new line. On that line, you are going to add the required comment that lets Liquibase know you are starting a new changeset. This line looks like “– changeset author:versionNumber”. Example: “– changeset elahren:1.1”. Then, add a line below your changeset comment and add the DDL script you would like to run on your database. Once you have added all the changes you would like to your changelog file, save and close the file, then open the Liquibase command prompt to execute those changes on your database.

If you would like to preview the changes Liquibase will run on your database, you can run the command “liquibase update-sql” which will show you all the SQL that will be executed, which will include your queries as well as queries Liquibase will run to track what you’re applying. In the below screenshot, the commands with a green square are the ones I included in my changesets, and the commands with a blue square are the ones that Liquibase will run to track the changes.
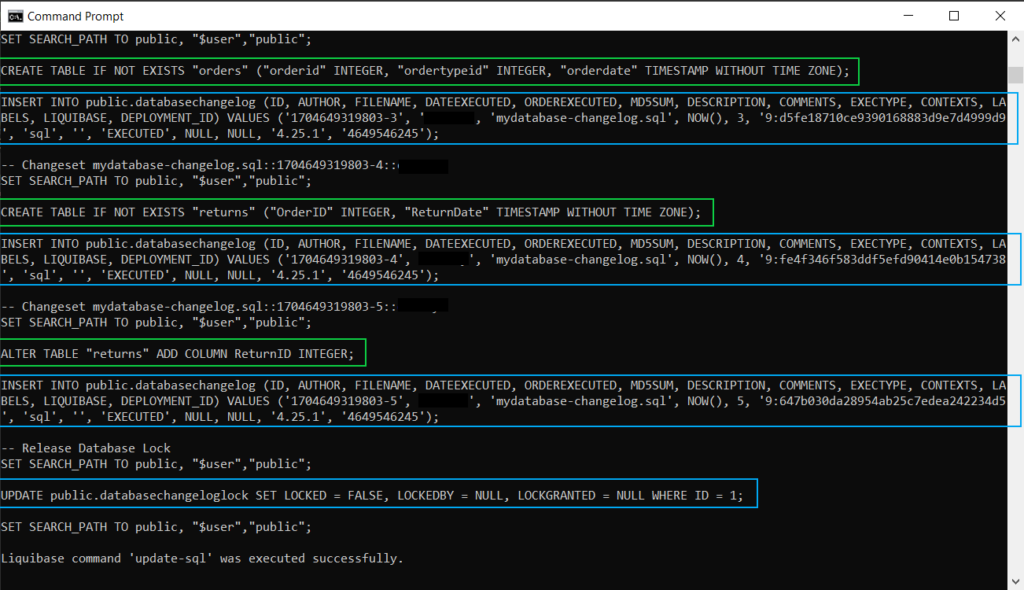
If the preview looks correct, you can then run the command “liquibase update” which will apply all the previously viewed SQL queries to your database. You can verify the changes have been successfully applied by opening your database in your normal IDE (e.g. PGAdmin) and confirm the changes.
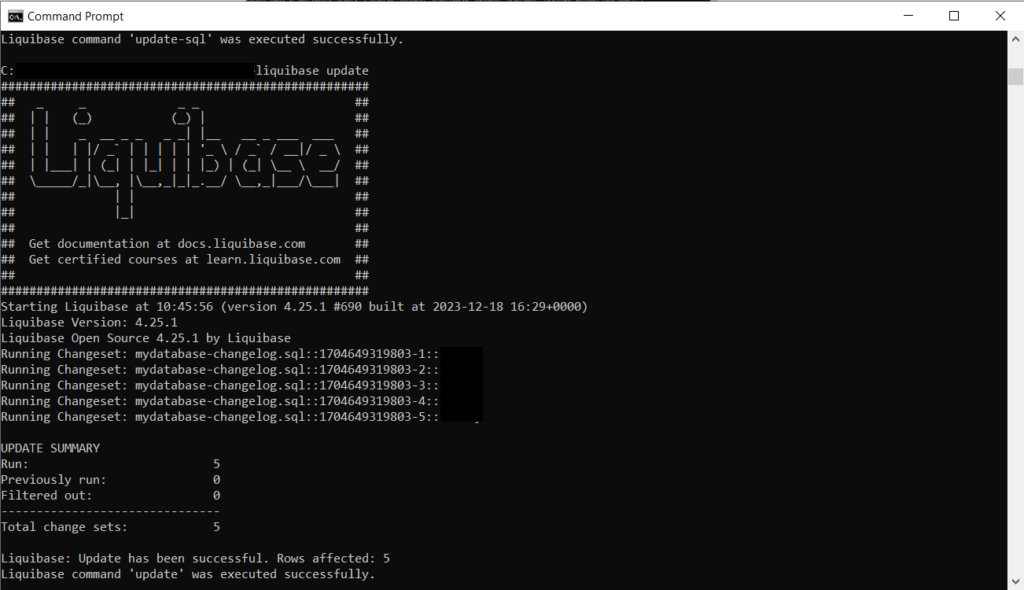
Method 2: Make Changes in your IDE
The process for making the changes in your IDE and then tracking those changes in Liquibase is almost exactly the same as the process we used to create the initial changelog file when setting up the project. It is as easy as making whatever database changes you want in your IDE and then opening the Liquibase CLI and running the “generate-changelog” command with either a new file name if you want to put it in a new changelog file, or use the same file name with the “--overwrite-output-file=true” argument.
If you are going to use the first option, writing to a new changelog file, it seems like you will then need to edit the file after creating it to remove any of the queries you didn’t create in your latest changes (since the command will try to recreate all objects in your database).
I’m not sure if this is the recommended workflow for tracking database changes, but it was a feature my team was hoping to get from the database change tracking tools we’ve been investigating, so I found a way to make it happen with Liquibase. If you want or need to have a “database-first” approach to change tracking (making changes directly to the database and then generating files to track that), instead of a “migration-first” type approach (making migration/change scripts and then applying that to your database), it appears that is technically possible with this tool.
Structuring your changelogs according to best practices
You can set up and structure your changelogs in any way that you would like, it’s your project, but Liquibase does have some ideas to help you stay organized. There are two different organization methods they recommend: object-oriented and release-oriented.
Object-oriented means you will create a different changelog file for each object or type of object being tracked in your database (e.g. one file for stored procedure changes, one file for table changes, etc.). I personally don’t like the idea of this organization method since it would mean you could be updating many files each time you make database changes, like if you’re updating procedures, tables, indexes, and views all for one release. However, having all the object types separated could also be a benefit, depending on how you normally complete your work.
Release-oriented means you make a new file for each release you make for your software/database. This method seems more familiar to me personally since it’s similar to the concept of migration scripts in Red-Gate’s SQL Change Automation or Flyway tools, where you can combine multiple database changes you’re making at once into a single file and deploy it all at once. This process could also work for organizations that use a more structured delivery system and not continuous delivery/agile development. That way you could put all of your changes for the week, month, or whatever development length into one file to associate with one particular release.
Whichever method you choose should work well if you set it up properly, the decision of which option to choose only depends on how you work and how you prefer to track that work.
Outstanding Questions
The first outstanding question I have about this tool right now is can you put DML scripts in your changelogs? That is something supported by Red-Gate’s SQL Change Automation and Flyway tools, which is what I’m used to. So far, I haven’t been able to figure out if that’s possible with Liquibase. Being able to deploy DML changes alongside a regular deployment really simplifies the process of some DMLs that you may need to run in your production environment, because it makes sure they go out with the deployment they are related to. An example of this is if you are adding a lookup type table (i.e. AccountTypes) and need to add the few records into that table after it’s created. Normally, you would need to run such a DML script manually after your deployment has completed. But SCA and Flyway allow you to put the DML in a deployable script that will automatically insert that data after the table is created. That of course can come with its own challenges, but it’s something I’ve really enjoyed with Red-Gate SQL Change Automation so I want it to be possible with Liquibase.
The second outstanding question I have about Liquibase is whether or not it can work with a secrets manager for database user passwords. How I set up my test project locally required me to put the password for the database user for Liquibase to be saved in cleartext in the properties file, which is not safe. For my purposes, it was fine since it’s a dummy database that doesn’t have any real data in it. But for production purposes, there is no way we would ever save a database user password in cleartext in a file. I haven’t had the chance to research this question more yet, so I’m not sure if the tool would work with a secrets manager or not.
Summary
When I first started working with Liquibase I was pretty frustrated with it since it was a totally new-to-me tool with documentation I didn’t find intuitive. But I kept working with it because I wanted to make it work for my organization and then just found it interesting to learn more about. I now feel fairly confident working with the tool in the ways my organization would need.
For being a tool with a completely free-to-use version, it seems like it has a good amount of features that many developers might need and could use for tracking and deploying changes to their databases. I can’t honestly say that I would prefer using this tool to Red-Gate’s SQL Change Automation or Flyway tools, which I currently work with, since they have a better use interface and seem to have more intuitive script creation processes. But Liquibase does seem like a useful tool that I could get used to working with given enough time. It’s worth a try to work with if your organization is working with a limited tool budget.